Last Updated on April 5, 2024 9:59 am by Laszlo Szabo / NowadAIs | Published on April 5, 2024 by Laszlo Szabo / NowadAIs
Stanford University’s Octopus V2: On-Device AI Beats GPT-4 – Key Notes
- Octopus V2, developed by Stanford University, is an on-device language model enhancing AI agents’ software task performance with high accuracy and low latency.
- Designed to address privacy and cost concerns, it’s ideal for edge devices, such as smartphones and VR headsets.
- Utilizes a two-stage process for function calling, achieving better accuracy and efficiency.
- Employs special tokens for improved function name prediction and tackles the imbalance in datasets with a weighted cross-entropy loss function.
- Trained using the Gemma-2B model with both full model and Lora training methodologies.
On-device Artificial Intelligence by Stanford University: Octopus V2
In the rapidly evolving landscape of AI agents and language models, the Octopus V2 outstands as an on-device language model for super agents. Developed by a team at Stanford University, this model empowers AI agents to perform a wide range of software tasks, including function calling, with exceptional accuracy and reduced latency.
The Octopus V2 addresses the concerns of privacy and cost associated with large-scale cloud-based language models, making it suitable for deployment on edge devices like smartphones, cars, VR headsets, and personal computers.
The Need for On-Device Language Models
Language models have changed the field of AI, allowing for natural language processing and understanding. However, relying on cloud-based models for function calling comes with drawbacks such as privacy concerns, high inference costs, and the need for constant Wi-Fi connectivity. Deploying smaller, on-device models can mitigate these issues, but they often face challenges like slower latency and limited battery life. The Octopus V2 aims to overcome these challenges by providing an efficient and accurate on-device language model.

Octopus V2: Enhancing Accuracy and Latency
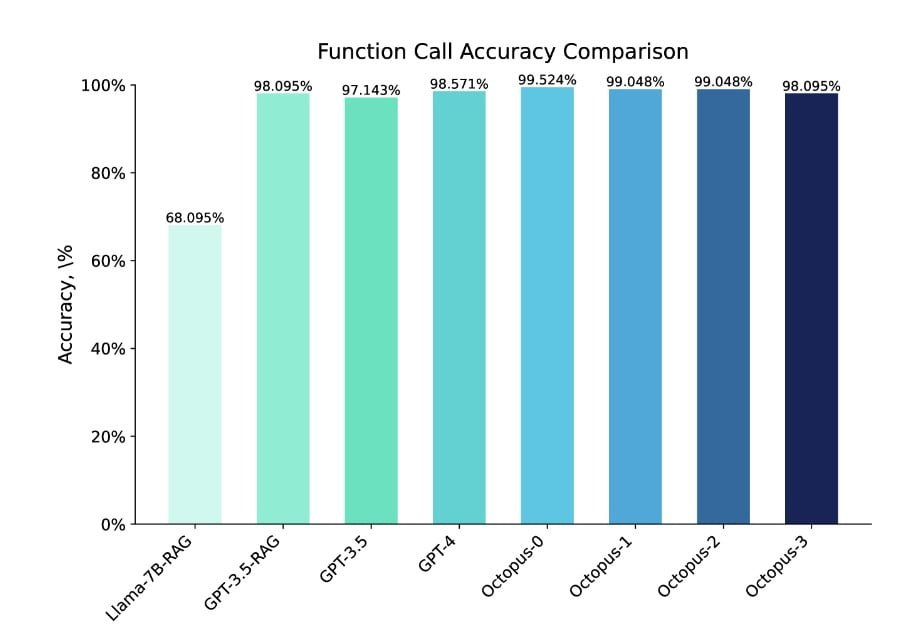
The Octopus V2 model surpasses the performance of GPT-4 in terms of both accuracy and latency. With 2 billion parameters, the Octopus V2 model reduces the context length by 95%, enabling faster and more efficient function calling. By fine-tuning the model with functional tokens and incorporating function descriptions into the training dataset, the Octopus V2 model achieves better performance in function calling compared to other models. In fact, it outperforms the Llama-7B model with a RAG-based function calling mechanism by enhancing latency by 35-fold.
Methodology: Causal Language Model as a Classification Model
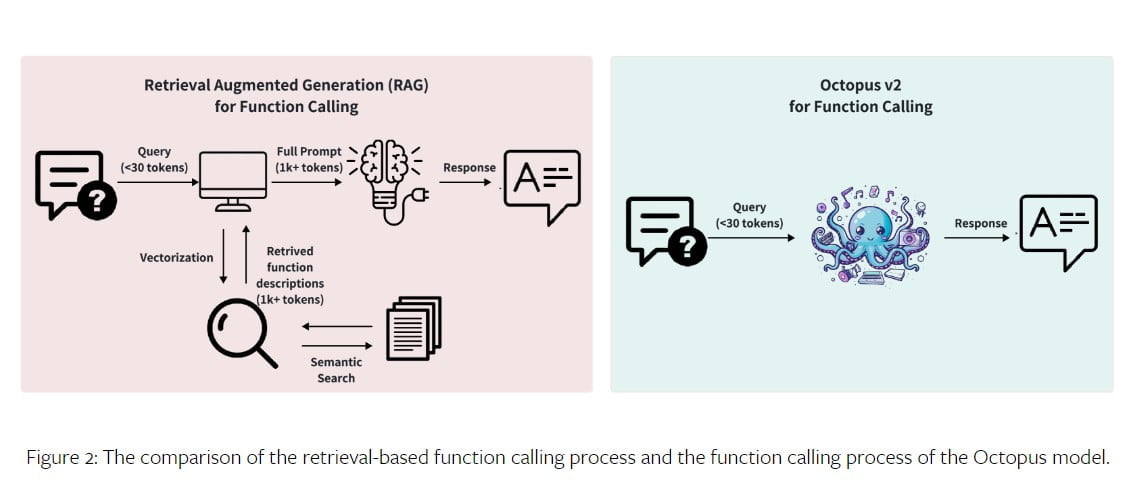
The Octopus V2 model utilizes a two-stage process for function calling: function selection and parameter generation. In the function selection stage, the model employs a classification model to accurately select the appropriate function from a pool of available options. This can be achieved through retrieval-based document selection or autoregressive models like GPT.
The parameter generation stage involves creating parameters for the selected function based on the user’s query and function description. The Octopus V2 model combines these two stages using a unified GPT model strategy, resulting in quicker inference speeds and system convenience.
Dataset Collection and Model Training
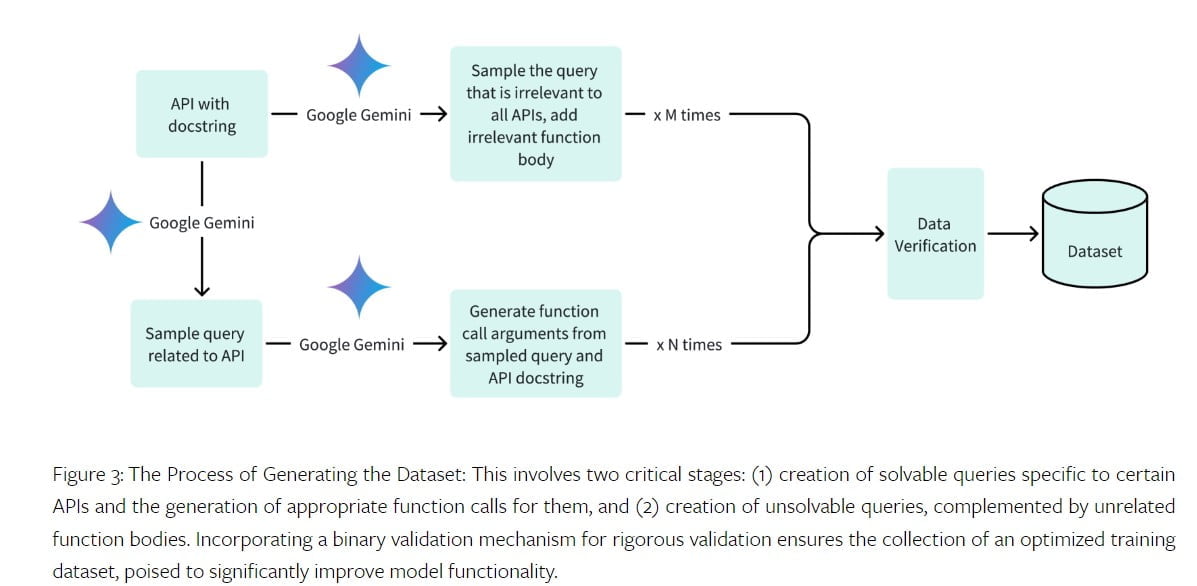
To train the Octopus V2 model, a high-quality dataset is essential. The dataset includes relevant queries, function call arguments, and function descriptions. The team at Stanford University collected datasets for different domains, including Android APIs, vehicle APIs, Yelp APIs, and DoorDash APIs. The dataset generation process involved generating positive queries and function call arguments for solvable queries, as well as negative samples for unsolvable queries. The dataset was verified using the Google Gemini API, ensuring accuracy and completeness.
The Octopus V2 model was trained using the Gemma-2B pretrained model and two different training methodologies: full model training and LoRA training. Full model training involved using an AdamW optimizer with a learning rate of 5e-5 and a warm-up step of 10. LoRA training, on the other hand, utilized a rank of 16 and applied LoRA to specific modules of the model. Both training methods achieved state-of-the-art results in terms of accuracy and latency.
Moreover, the Octopus V2 model’s training dataset size can be adjusted to achieve cost efficiency without compromising accuracy. Training the model with a smaller dataset size, ranging from 100 to 1,000 data points per API, still yields high accuracy rates, making it accessible for individuals seeking to train their own Octopus models.
Benchmarking and Performance Evaluation
The Octopus V2 model underwent comprehensive benchmarking and evaluation to assess its effectiveness in generating accurate function calls. The model’s accuracy and response time were compared to premier models in the field, such as GPT-4 and GPT-3.5. The Octopus V2 model outperformed these models in terms of accuracy, achieving an accuracy rate of 99.524% in the evaluation dataset.
The model also demonstrated significantly reduced latency, completing a function call within 0.38 seconds. The Octopus V2 model’s performance was evaluated in various domains, including Android function calls, vehicle function calls, Yelp APIs, and DoorDash APIs, showcasing its versatility and adaptability.
Fine-tuning with Special Tokens
A unique aspect of the Octopus V2 model is the incorporation of special tokens into the tokenizer and the expansion of the language model’s head. These special tokens represent function names and enable accurate function name prediction.
To address the imbalanced dataset challenge caused by the introduction of special tokens, a weighted cross-entropy loss function is utilized during training. This weighted loss function assigns higher weights to special tokens, improving convergence and overall model performance.
Conclusion and Future Works
The Octopus V2 model represents a significant advancement in on-device language models for super agents. Its ability to perform accurate function calling with reduced latency makes it suitable for a wide range of applications, from smartphones to VR headsets. The model’s high accuracy and efficiency pave the way for improved AI agent performance in real-world scenarios.
In the future, further research and development can focus on expanding the model’s capabilities, exploring new domains, and optimizing its performance for specific applications.
Definitions
- Octopus V2: An advanced on-device language model created by Stanford University, designed to significantly enhance the capabilities of AI agents by enabling them to perform software tasks with unprecedented accuracy and speed.
- Stanford University: A prestigious research university known for its significant contributions to various fields, including artificial intelligence and computer science.
- On-Device Language Models: AI models that operate directly on local devices, such as smartphones or computers, without the need for cloud processing, emphasizing privacy and reducing reliance on constant internet connectivity.
- API: Application Programming Interface, a set of protocols and tools for building software and applications, enabling communication between different software components.
- Gemma-2B: A pretrained model used in the development of Octopus V2 for achieving high-quality training outcomes.
- Lora Training: A training methodology that applies Low-Rank Adaptation to specific modules of an AI model to enhance its performance without the need for extensive retraining.
Frequently Asked Questions
- What sets Octopus V2 apart from other on-device language models?
- Octopus V2 stands out for its ability to perform a wide range of software tasks with remarkable accuracy and reduced latency, all while addressing privacy and cost concerns of cloud-based models.
- How does Octopus V2 enhance AI agent performance in real-world applications?
- By reducing context length by 95% and fine-tuning with functional tokens, Octopus V2 enables AI agents to execute function calls more efficiently, outperforming previous models like GPT-4 and Llama-7B in accuracy and latency.
- What are the benefits of using Octopus V2 for developers and end-users?
- For developers, Octopus V2 offers a powerful tool for creating responsive and capable AI applications on edge devices. End-users benefit from faster, more accurate interactions with AI agents, enhancing the overall user experience.
- Can Octopus V2 be adapted to various domains and applications?
- Yes, Octopus V2’s versatility has been demonstrated across different domains, including Android APIs, vehicle APIs, and Yelp APIs, showcasing its adaptability and effectiveness in various settings.
- What future developments can we expect from the Octopus V2 model?
- Future research will focus on expanding Octopus V2’s capabilities to more domains, optimizing its performance for specific applications, and exploring new methodologies to further enhance its accuracy and efficiency.