Last Updated on augusztus 12, 2024 1:11 du. by Laszlo Szabo / NowadAIs | Published on augusztus 12, 2024 by Laszlo Szabo / NowadAIs
Viszlát, fordulóalapú mesterséges intelligencia: Helló, hallgat-amíg-beszél nyelvi modell – Főbb megjegyzések
- A hallgatás közben beszélő nyelvi modell (Listening-While-Speaking Language Model, LSLM) valós időben integrálja a hallgatóságot és a beszédet, kiküszöbölve a fordulóalapú párbeszédrendszerek korlátait.
- A Shanghai Jiao Tong University és a ByteDance által kifejlesztett LSLM kétcsatornás architektúrát használ, amely a token-alapú TTS-t és a streaming SSL kódolót kombinálja.
- Az LSLM hatékonyan kezeli a megszakításokat és a háttérzajt, és különböző kísérleti beállításokban bizonyította robusztusságát és érzékenységét.
- A középső fúziós stratégia optimalizálja az interakciót azáltal, hogy minden egyes Transformer blokkban egyesíti a hallgatási és a beszédcsatornákat, így biztosítva a zökkenőmentes párbeszédélményt.
Bevezetés
Az ember-számítógép interakció (HCI) területén a természetesebb és intuitívabb kommunikációra való törekvés volt a technológiai fejlődés hajtóereje. Az emberi interakció legalapvetőbb formájaként a párbeszéd már régóta a társalgási mesterséges intelligencia rendszerek szent grálja. A beszédnyelvi modellek (SLM) terén a közelmúltban elért áttörések kétségtelenül javították a beszédalapú társalgási mesterséges intelligencia képességeit, azonban ezeket a rendszereket továbbra is korlátozza a fordulóalapú jellegük, mivel nem képesek valós idejű, megszakítás nélküli interakciókra.
Ez a korlátozás újból a teljes duplex modellezés (FDM) feltárására helyezte a hangsúlyt az interaktív beszédnyelvi modellekben (iSLM), a kutatók pedig a megszakítás és a zökkenőmentes oda-vissza kommunikáció kvintesszenciális képességének feloldására törekedtek. E törekvés közepette egy friss innováció bukkant fel: a Listening-While-Speaking Language Model (LSLM), egy végponttól végpontig tartó rendszer, amelyet az emberek és a gépek társalgási módjának frissítésére terveztek.
A fordulóalapú párbeszédrendszerek korlátai
A hagyományos beszéd-nyelvi modellek jellemzően a fordulóalapú megközelítésre támaszkodtak, ahol a hallgatás és a beszéd elszigetelt fázisokban történik. Ez az elszigetelt struktúra, amely gyakran különálló automatikus beszédfelismerő (ASR) és szövegből beszédbe (TTS) modulokat tartalmaz, eredendően késleltetési problémákhoz vezetett, és képtelen volt hatékonyan kezelni a valós idejű megszakításokat. A SpeechGPT és a LauraGPT neves modellek kitolták a társalgási mesterséges intelligencia határait, de továbbra is ezekre a fordulóalapú paradigmákra korlátozódnak, és nem képesek biztosítani a valóban természetes ember-számítógép párbeszédhez szükséges gördülékeny interakciót.
Az LSLM születése: A valós idejű interakcióban tátongó szakadék áthidalása
A Shanghai Jiao Tong Egyetem és a ByteDance kutatócsoportja felismerve a zökkenőmentesebb és érzékenyebb társalgási élmény iránti igényt, bevezette a Listening-While-Speaking Language Model (LSLM) nevű modellt. Ez a modell a fordulóalapú rendszerek korlátainak leküzdésére törekszik azáltal, hogy a hallgatási és a beszédkészségeket egyetlen, végponttól végpontig tartó architektúrába integrálja.
Az LSLM kétcsatornás megközelítése
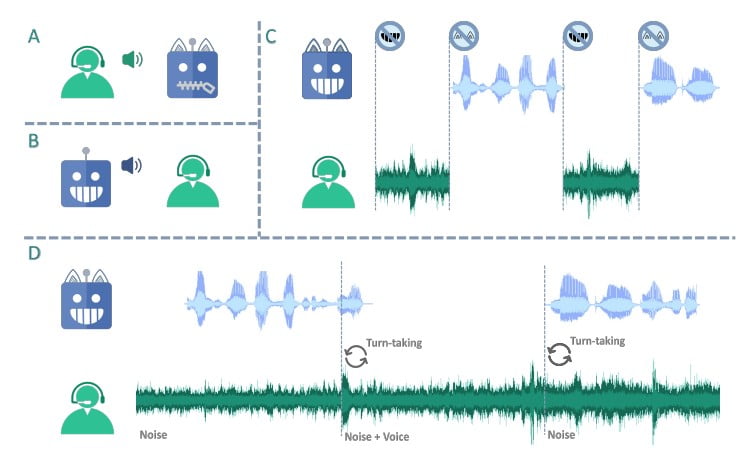
Az LSLM egyedi felépítése a kétcsatornás architektúra körül forog, amely kombinálja a csak token-alapú dekódert a beszédgeneráláshoz és a streaming önfelügyelt tanulás (SSL) kódolót a valós idejű hangbevitelhez. Ez a megközelítés lehetővé teszi, hogy a modell egyesítse a hallgatói és a beszédcsatornát, így valós időben érzékeli a sorváltást, és dinamikusan reagál a felhasználó bemenetére.
A beszédcsatorna: Autoregresszív Token-alapú TTS
A korábbi, autoregresszív és nem autoregresszív megközelítésekre támaszkodó modellektől eltérően az LSLM egy token-alapú TTS rendszer alkalmazásával egyszerűsíti a beszédgenerálás folyamatát. Ez a beállítás lehetővé teszi, hogy a modell jobban összpontosítson a szemantikai információkra, javítva a válaszok egyértelműségét és relevanciáját, miközben a beszédszintézis előtti kiterjedt előfeldolgozás szükségességének kiküszöbölésével fokozza a valós idejű interakciót.
A hallgatói csatorna: Streaming SSL kódoló
A hallgatási oldalon az LSLM egy streaming SSL kódolót használ a bejövő hangjelek folyamatos feldolgozásához. Ez a kódoló a bemeneti hangot folyamatos beágyazásokká alakítja, amelyeket aztán egy olyan térbe vetít, amely zökkenőmentesen integrálható a beszélő tokenekkel. Ez az integráció biztosítja, hogy a modell mindkét csatorna információit hasznosítani tudja a beszédgenerálási folyamat során.
Fúziós stratégiák: A valós idejű interakció és a beszédgenerálás egyensúlyban tartása
A hallgatói és a beszédcsatorna közötti szinergia optimalizálása érdekében a kutatók három fúziós stratégiát vizsgáltak: korai fúzió, középső fúzió és késői fúzió. A gondos értékelés után a középső fúziós megközelítés bizonyult a leghatékonyabbnak, amely optimális egyensúlyt teremt a valós idejű interakció és a beszédgenerálás képességei között.
A középső fúziós módszerben a hallgató és a beszélő csatornákat minden egyes Transformer blokkban egyesítik, lehetővé téve a modell számára, hogy a beszédgenerálás során folyamatosan felhasználja mindkét csatorna tanulságait. Ez az integráció biztosítja, hogy az LSLM zökkenőmentesen tudja kezelni a megszakításokat, és képes fenntartani a koherens és reagáló párbeszédfolyamot, valós időben alkalmazkodva a felhasználó bemenetéhez.
Az LSLM teljesítményének értékelése: Robusztusság és érzékenység
Az LSLM képességeit két kísérleti környezetben teszteltük: parancsalapú FDM és hangalapú FDM. A parancsalapú forgatókönyvben a modell bizonyította a háttérzajjal szembeni robusztusságát, mivel zajos környezetben is hatékonyan reagált a konkrét parancsokra. A hangalapú környezetben viszont az LSLM érzékenységét értékelték a különböző hangszórók megszakításaira, bemutatva az új hangok és utasítások felismerésére és az azokhoz való alkalmazkodásra való képességét.
E kísérletek eredményei rávilágítottak az LSLM lenyűgöző teljesítményére, kiemelve annak lehetőségét, hogy forradalmasíthatja az interaktív beszéd-nyelvi modellek területét. Különösen a középső fúziós stratégia bizonyult döntő tényezőnek a valós idejű interakció és a beszédgenerálás követelményeinek kiegyensúlyozásában, zökkenőmentes és érzékeny felhasználói élményt nyújtva.
A társalgási mesterséges intelligencia határainak kiteljesedése
A Listening-While-Speaking Language Model (LSLM) jelentős előrelépést jelent az interaktív beszéd-nyelvi modellek területén. A fordulóalapú rendszerek korlátainak kezelésével és a robusztus, valós idejű interakciós képesség bevezetésével az LSLM megnyitja az utat a természetesebb és gördülékenyebb ember-számítógép párbeszédek előtt. Ez a kutatás rávilágít a teljes duplex képességek SLM-ekbe való integrálásának fontosságára, bemutatva, hogy az ilyen fejlesztések hogyan növelhetik a társalgási AI alkalmazhatóságát valós forgatókönyvekben.
Következtetés: A társalgási mesterséges intelligencia teljes potenciáljának felszabadítása
A hallgatás közbeni beszéd közbeni nyelvi modell (Listening-While-Speaking Language Model, LSLM) átalakító áttörést jelent az interaktív beszéd-nyelvi modellek területén. A hallgató és beszélő képességek zökkenőmentes integrálásával ez a konstrukció legyőzi a hagyományos, fordulóalapú rendszerek korlátait, és a természetesebb és gördülékenyebb ember-számítógép párbeszéd új korszakát nyitja meg. Mivel az intuitív és érzékeny társalgási mesterséges intelligencia iránti igény egyre nő, az LSLM valós idejű interakciót elősegítő és a megszakításokat könnyedén kezelő képessége révén változást hoz a valóban zökkenőmentes ember és mesterséges intelligencia közötti kommunikációra való törekvésben.
Leírások
- Teljes duplex modellezés (FDM): A fordulóalapú modellekkel ellentétben, ahol az egyik félnek meg kell várnia, amíg a másik befejezi a beszédet.
- Token-alapú, csak dekóderes TTS: Olyan rendszer, amely tokeneket, azaz adatdarabokat használ a beszéd generálásához, lehetővé téve a mesterséges intelligencia számára, hogy gyorsabban és pontosabban válaszoljon, mivel a kiterjedt adatok előzetes feldolgozása helyett a jelentésre összpontosít.
- Folyamatos önfelügyelt tanulás (SSL) kódoló: A mesterséges intelligencia olyan típusa, amely folyamatosan dolgozza fel a hangbemeneteket, és a hangokat olyan adatokká alakítja, amelyeket a modell megérthet és felhasználhat a valós idejű interakcióhoz.
- Transzformátor blokk: A mesterséges intelligenciamodellek olyan összetevője, amely a bemeneti adatok különböző részeire egyidejűleg összpontosítva segíti a nyelv feldolgozását és megértését, javítva a sebességet és a pontosságot.
- Fúziós stratégiák: A különböző csatornákból származó adatok AI-modellbe történő integrálására használt technikák. A korai, középső és késői fúziós stratégiák határozzák meg, hogy a teljesítmény optimalizálása érdekében hogyan és mikor kombinálják az adatokat a feldolgozás során.
- Parancsalapú FDM: Olyan kísérleti elrendezés, amelyben a mesterséges intelligenciamodell meghatározott hangparancsokra reagál, tesztelve a háttérzaj és megszakítások közepette történő működésének képességét.
- Hangalapú FDM: Kísérleti forgatókönyv, amely azt értékeli, hogy a mesterséges intelligencia mennyire jól kezeli a különböző hangokat és megszakításokat, felmérve az új hangszórókhoz és utasításokhoz való alkalmazkodóképességét.
Gyakran ismételt kérdések
- Mi az a Hallgatás közbeni beszéd közbeni nyelvi modell (LSLM)? A Hallgatás közben beszélő nyelvi modell (LSLM) egy fejlett mesterséges intelligencia rendszer, amelyet úgy terveztek, hogy a hallgatás és a beszéd képességének integrálásával valós idejű párbeszédet folytasson. A hagyományos modellekkel ellentétben zökkenőmentes oda-vissza kommunikációt tesz lehetővé, sorbanállás nélkül.
- Hogyan kezeli az LSLM a beszélgetés közbeni megszakításokat? Az LSLM kétcsatornás architektúrát használ egy streaming SSL kódolóval, amely folyamatosan feldolgozza a hangbemenetet. Ez a beállítás lehetővé teszi, hogy zökkenőmentesen felismerje a megszakításokat, és alkalmazkodjon azokhoz, fenntartva a koherens párbeszédfolyamot még akkor is, ha új hangok vagy parancsok kerülnek bevezetésre.
- Mitől hatékony a középső fúziós stratégia az LSLM-ben? A középső fúziós stratégia minden egyes transzformátorblokkban egyesíti a hallgató és a beszélő csatornákat, így a modell mindkét információkészletet hasznosítani tudja a párbeszéd során. Ez a megközelítés egyensúlyt teremt a valós idejű interakció és a beszédgenerálás között, növelve a mesterséges intelligencia reakciókészségét és koherenciáját.
- Hogyan kezeli az LSLM a háttérzajt a működése során? Parancsalapú kísérleti beállításokban az LSLM bizonyította robusztusságát azáltal, hogy hatékonyan kiszűrte a háttérzajt, és a konkrét parancsokra összpontosított. Fejlett feldolgozási képességei még zajos környezetben is pontos válaszokat biztosítanak.
- Milyen lehetséges alkalmazási területei vannak a Listening-While-Speaking Language Modelnek? Az LSLM javíthatja az ember-számítógép interakciókat különböző területeken, többek között az ügyfélszolgálat, az intelligens otthoni eszközök és a virtuális asszisztensek területén. A valós idejű párbeszéd és a megszakítások kezelésére való képessége ideális a zökkenőmentes és intuitív kommunikációt igénylő forgatókönyvekhez.