
Last Updated on február 28, 2024 10:08 de. by Laszlo Szabo / NowadAIs | Published on február 28, 2024 by Laszlo Szabo / NowadAIs
Bemutatkozik az EMO: Emote Portrait Alive – Portrékból éneklő szenzációk az Alibaba AI segítségével – Key Notes:
- Az Alibaba EMO egy audio2video diffúziós modellt használ a valósághű portrévideókhoz.
- Az EMO kifejező pontossággal fokozza a beszélőfejes videók generálását.
- Felülmúlja a hagyományos korlátokat, és árnyalt arckifejezéseket kínál audiojelekből.
Ismerje meg az Alibaba EMO-t: Emote Portrait Alive (Emote Portrait Alive)
Az elmúlt években a kép- és videogenerálás területén jelentős fejlődésnek lehettünk tanúi.
Az egyik legfrissebb fejlesztés ezen a területen az EMO: Emote Portrait Alive, az Alibaba Group’s Institute for Intelligent Computing által bevezetett keretrendszer.
Az EMO egy audio2videó diffúziós modellt használ, hogy kifejező portrévideókat hozzon létre figyelemre méltó realizmussal és pontossággal.

A diffúziós modellek és a legmodernebb neurális hálózati architektúrák erejét kihasználva az EMO a beszélőfejes videók generálásában elérhető határokat feszegeti.
Az érzelmes portrévideók iránti igény
A valósághű és kifejező beszélőfejes videók generálása régóta kihívást jelent a számítógépes grafika és a mesterséges intelligencia területén.
A hagyományos megközelítések gyakran nem képesek az emberi kifejezések teljes spektrumának megragadására, és nem képesek természetes és árnyalt arcmozgásokat produkálni.
E korlátok kiküszöbölésére az Alibaba Group kutatói olyan keretrendszer létrehozásába kezdtek, amely képes a hangjelzéseket pontosan élethű arckifejezésekké alakítani.
Az EMO keretrendszer megértése
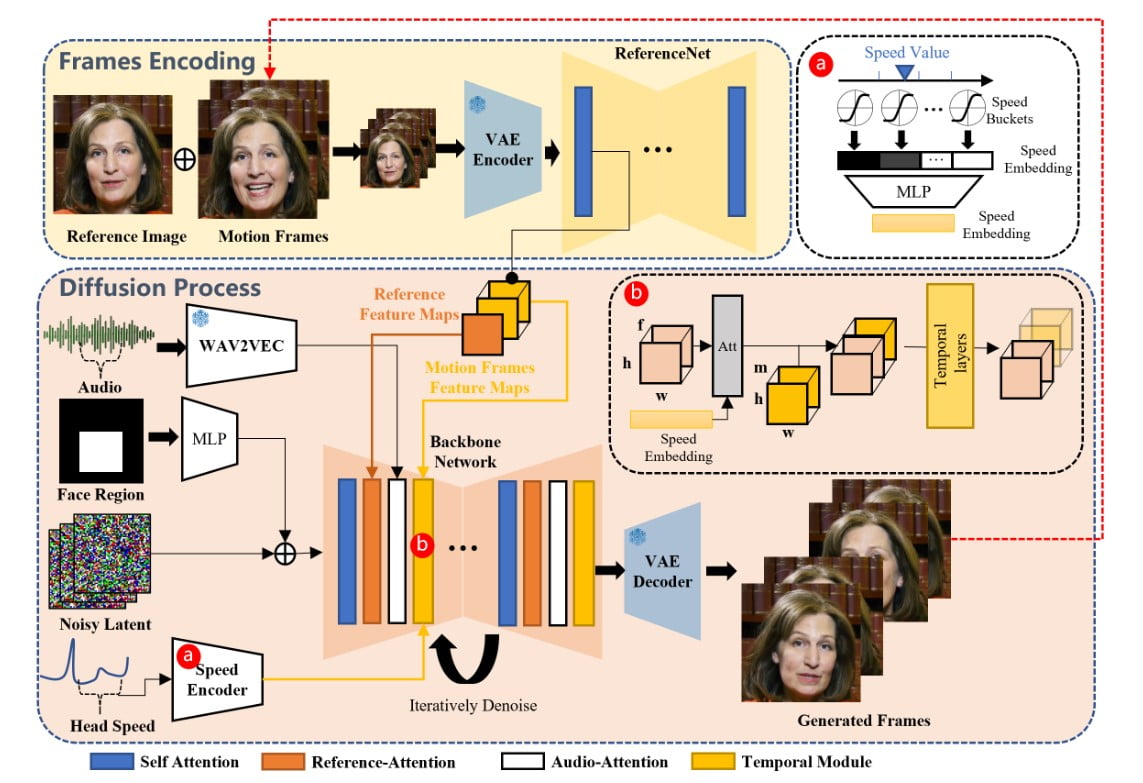
Az EMO keretrendszer egy kétlépcsős folyamat, amely az audio- és vizuális információkat kombinálva rendkívül kifejező portrévideókat hoz létre.
A kezdeti szakaszban, amelyet Frames Encodingnak nevezünk, egy ReferenceNet nevű neurális hálózat egyetlen referenciaképből és mozgáskockákból vonja ki a jellemzőket. Ez a kódolási folyamat megalapozza a későbbi diffúziós folyamatot.
A diffúziós folyamat szakaszában az EMO egy előre betanított hangkódolót használ a hangbeágyazás feldolgozásához.
Az arcrégió maszkja több képkockás zajjal van integrálva, ami az arcképek generálását szabályozza.
A referencia-figyelem és hang-figyelem mechanizmusokat tartalmazó Backbone Network döntő szerepet játszik a karakter identitásának megőrzésében és mozgásának modulálásában.
Ezen kívül Temporális modulokat alkalmaznak az időbeli dimenzió manipulálására és a mozgás sebességének beállítására.
Ezen innovatív technikák kombinációja lehetővé teszi az EMO számára, hogy kifejező arckifejezésekkel, különböző fejtartásokkal és a bemeneti hang hosszától függő tetszőleges időtartamú, vokális avatárvideókat hozzon létre.
Fejlődés a vokális avatarok generálásában
Az EMO a hagyományos beszélőfejes videókon túlmutat a vokális avatárgenerálás koncepciójának bevezetésével.
Az EMO egyetlen karakterkép és egy énekhang – például éneklés – bevitelével képes kifejező arckifejezésű, különböző fejpózokkal rendelkező és a bemeneti hang hosszától függően tetszőleges időtartamú vokális avatar-videókat generálni.
Éneklő avatárok
Az EMO képes olyan éneklő avatárokat generálni, amelyek meggyőzően utánozzák a referencia karakter arckifejezését és fejmozgását.
Legyen szó Ed Sheeran “Perfect” vagy Dua Lipa “Don’t Start Now” című dalának előadásáról, az EMO figyelemre méltó pontossággal és kifejezőerővel kelti életre a karaktert.
A generált videók élethű előadásmódjukkal és a hanggal való zökkenőmentes szinkronizálással képesek lenyűgözni a közönséget.
Többnyelvű és multikulturális kifejezések
Az EMO keretrendszer egyik fő erőssége, hogy képes támogatni a különböző nyelvű dalokat és életre kelteni a különböző portréstílusokat.
A hangok hangszínváltozatainak intuitív felismerésével az EMO képes dinamikus és kifejezésekben gazdag avatárokat létrehozni, amelyek tükrözik a különböző nyelvek kulturális árnyalatait.
David Tao “Melody” című dalának mandarin nyelvű feldolgozásától kezdve a “進撃の巨人” főcímdal japán nyelvű feldolgozásáig az EMO lehetővé teszi az alkotók számára, hogy felfedezzék a többnyelvű és multikulturális karakterábrázolás lehetőségeit.
Gyors ritmus és kifejező mozgás
Az EMO kiválóan megragadja a gyors ritmusok lényegét, és kifejező mozgásokat biztosít, amelyek szinkronban vannak a hanggal.
Legyen szó Leonardo DiCaprio rappeléséről Eminem “Godzilla” című dalára vagy KUN KUN “Rap God” című előadásáról, az EMO biztosítja, hogy még a leggyorsabb szövegek is precízen és dinamikusan jelenjenek meg.
Ez a képesség új utakat nyit meg az olyan magával ragadó tartalmak létrehozásához, mint például a zenei videók vagy előadások, amelyek bonyolult szinkronizálást igényelnek a zene és a vizuális elemek között.
Az éneklésen túl: Beszélgetés különböző karakterekkel
Bár az EMO a kivételes éneklő avatarok generálásáról ismert, nem korlátozódik csupán az éneklésből származó hangbemenetek feldolgozására.
Ez a keretrendszer képes különböző nyelveken beszélt hangot is befogadni, és animálni a régmúlt korok portréit, festményeket, 3D modelleket és mesterséges intelligencia által generált tartalmakat.
Azáltal, hogy ezeket a karaktereket élethű mozgással és realizmussal ruházza fel, az EMO kiterjeszti a karakterek ábrázolásának lehetőségeit többnyelvű és multikulturális kontextusokban.
Beszélgetések ikonikus figurákkal
Képzeld el, hogy beszélgetsz Audrey Hepburnnel, az AI Chloe-val a Detroit Become Humanből, vagy akár a rejtélyes Mona Lisával – az EMO képes életre kelteni ezeket az ikonikus figurákat azáltal, hogy animálja a portréjukat és szinkronizálja a szájmozgásukat a beszélt hanggal.
Legyen szó egy interjúklipről vagy egy Shakespeare-monológról, az EMO gondoskodik arról, hogy a karakter arckifejezése és fejmozgása pontosan közvetítse a beszélgetés árnyalatait.
Színészeken átívelő előadások
Az EMO a kreativitás teljesen új területét nyitja meg azzal, hogy a filmszereplők portréi különböző nyelveken és stílusokban adhatnak elő monológokat vagy előadásokat.
Joaquin Phoenix Joker alakításától kezdve SongWen Zhang QiQiang Gao-ig a “The Knockout”-ból, az EMO lehetővé teszi az alkotók számára, hogy felfedezzék a színészeken átívelő előadások lehetőségeit.
Ez a funkció kitágítja a karakterábrázolás horizontját, lehetővé téve, hogy különböző filmek vagy tévéműsorok szereplőit zökkenőmentesen integráljuk egyetlen videóba.
A realizmus határainak feszegetése
Az EMO keretrendszer a portrévideók készítésénél a realizmus határait feszegeti.
Az EMO a köztes 3D modellek vagy az arc tájékozódási pontjainak megkerülésével zökkenőmentes képkockaátmeneteket és következetes identitásmegőrzést biztosít a videó teljes hosszában.
A stabil vezérlési mechanizmusok, például a sebességszabályozó és az arctartomány-szabályozó integrálása növeli a stabilitást a generálási folyamat során. Ezek a szabályozók finom vezérlőjelekként működnek, amelyek nem veszélyeztetik a végső generált videók sokszínűségét és kifejezőerejét.
Képzés és adatállomány
Az EMO modell betanításához egy hatalmas és változatos audio-videó adathalmazt hoztunk létre, amely több mint 250 órányi felvételből és több mint 150 millió képből áll.
Ez a kiterjedt adathalmaz a tartalmak széles skáláját öleli fel, beleértve beszédeket, film- és televíziós klipeket, énekes előadásokat, és több nyelvet, például a kínait és az angolt is lefedi.
A beszéd- és énekvideók gazdag választéka biztosítja, hogy a képzési anyag az emberi kifejezések és énekstílusok széles spektrumát rögzítse, szilárd alapot biztosítva az EMO fejlesztéséhez.
Kísérleti eredmények és felhasználói tanulmány

Az EMO teljesítményének értékelése érdekében kiterjedt kísérleteket és összehasonlításokat végeztünk a HDTF-adatkészleten.
Az eredmények azt mutatták, hogy az EMO több mérőszám, például FID, SyncNet, F-SIM és FVD tekintetében is felülmúlta a jelenlegi legkorszerűbb módszereket, köztük a DreamTalk, a Wav2Lip és a SadTalker módszereket.
A felhasználói tanulmány és a kvalitatív értékelések továbbá megerősítették, hogy az EMO képes rendkívül természetes és kifejező beszélő és éneklő videók létrehozására, és az eddigi legjobb eredményeket érte el.
Korlátozások és jövőbeli irányok
Bár az EMO lenyűgöző képességeket mutat a kifejező portrévideók készítésében, vannak még korlátok, amelyekkel foglalkozni kell.
A keretrendszer nagymértékben függ a bemeneti hang és a referenciakép minőségétől, és az audiovizuális szinkronizálás javítása tovább fokozhatja a generált videók realizmusát.
A jövőbeli kutatások emellett vizsgálhatják a fejlettebb érzelemfelismerési technikák integrálását, hogy még árnyaltabb arckifejezéseket tegyenek lehetővé.
Fogalommeghatározások
- EMO: Emote Portrait Alive: Az Alibaba által készített keretrendszer kifejező portrévideók generálására hangból, fejlett mesterséges intelligencia technikákat alkalmazva a realizmus és a pontosság érdekében.
- Avatár: Digitális reprezentáció vagy karakter, amelyet gyakran virtuális környezetekben vagy online felhasználói identitásként használnak.
- 3D modellek: Bármely tárgy vagy felület digitális ábrázolása három dimenzióban, amelyet a számítógépes grafikában és az animációban használnak.
- HDTF-adatkészlet: A mesterséges intelligenciában és a gépi tanulásban használt kiváló minőségű adatállomány, bár a konkrét kontextus és tartalom alkalmazásonként eltérő lehet.
- Alibaba (mesterséges intelligenciával kapcsolatos): Vezető globális vállalat, amely az Intelligens Számítástechnikai Intézetén keresztül olyan élvonalbeli AI-technológiákat fejleszt különböző alkalmazásokhoz, mint az EMO.
Gyakran ismételt kérdések
- Mi az EMO: Emote Portrait Alive?
Az EMO az Alibaba innovatív keretrendszere, amely fejlett mesterséges intelligencia segítségével hangbemenetből kifejező portrévideókat készít. - Hogyan javítja az EMO: Emote Portrait Alive a portrévideókat?
Az EMO realizmust és érzelmi mélységet kölcsönöz a portrévideóknak, pontosan lefordítva a hangjelzéseket arckifejezésekké. - Az EMO: Emote Portrait Alive képes több nyelven is létrehozni avatárokat?
Igen, az EMO támogatja a többnyelvű hangbevitelt, lehetővé téve a kulturális árnyalatokat tükröző, kifejező avatárokat. - Milyen típusú tartalmakat képes animálni az EMO: Emote Portrait Alive?
Az EMO képes élethű mozgással animálni különböző forrásokból származó portrékat, köztük történelmi személyiségeket, festményeket és 3D modelleket. - Miben különbözik az EMO: Emote Portrait Alive más AI-technológiáktól?
Az EMO kiemelkedik a rendkívül kifejező és valósághű beszélő és éneklő videók létrehozásának képességével, ami a vokális avatárgenerálás határait feszegeti.







