Last Updated on április 23, 2024 1:02 du. by Laszlo Szabo / NowadAIs | Published on április 23, 2024 by Laszlo Szabo / NowadAIs
Lásd a láthatatlant: Az Adobe VideoGigaGAN AI modellje lenyűgöző részletességet hoz az elmosódott videókba – fő pontok
- Az Adobe VideoGigaGAN AI modellje jelentősen javítja az alacsony felbontású videók felbontását, biztosítva a finom részleteket és az időbeli konzisztenciát.
- A GigaGAN képmintavételezéshez használt, videókra kiterjesztett technológiájára épül.
- Aszimmetrikus U-háló architektúrát használ további időbeli figyelemrétegekkel a képkockák közötti konzisztencia fenntartása érdekében.
- Olyan fejlett modulokkal, mint az áramlásvezérelt terjedés, kiküszöböli a VSR olyan gyakori problémáit, mint a villódzó műalkotások és az aliasing.
- Kiváló teljesítményt mutat a videók 8×-os felbontásig történő felskálázása során, miközben megőrzi a bonyolult részleteket és a valósághű textúrákat.
Bevezetés
A videó szuperfelbontás (VSR) régóta kihívást jelentő feladat a számítógépes látás és a grafika területén. A cél az alacsony felbontású videók felbontásának növelése, a finom részletek visszanyerése és a képkockák időbeli konzisztenciájának biztosítása. Míg a korábbi VSR-megközelítések lenyűgöző időbeli konzisztenciát mutattak, a nagyfrekvenciás részletek előállításában gyakran alulmaradnak, ami a képi megfelelőikhez képest elmosódott eredményekhez vezet.
AzAdobe, a terület egyik vezető innovátora bemutatta a VideoGigaGAN-t, egy olyan generatív mesterséges intelligencia modellt, amely ezt az alapvető kihívást kezeli. A nagyméretű képfelbontójuk, a GigaGAN sikerére építve a VideoGigaGAN új magasságokba emeli a videók szuperfelbontását, és elképesztő részletességű és egyenletes videókat eredményez.
A videó szuperfelbontás kihívása
[/video]

Az időbeli konzisztencia és a nagyfrekvenciás részletek elérése a videó szuperfelbontásban jelentős kihívást jelent. A korábbi megközelítések az időbeli konzisztencia fenntartására összpontosítottak, regresszió alapú hálózatok és optikai áramlási összehangolási technikák alkalmazásával. Bár ezek a módszerek biztosítják a képkockák közötti sima átmenetet, gyakran feláldozzák a részletes megjelenések és a valósághű textúrák létrehozását. Ez a korlátozás motiválta az Adobe kutatóit, hogy feltárják a generatív adverzális hálózatokban (GAN) rejlő lehetőségeket a videók szuperfelbontásában.
VideoGigaGAN: A képfelbontás sikerének kiterjesztése a videókra is
A VideoGigaGAN a GigaGAN, az Adobe által kifejlesztett nagyméretű GAN-alapú képfelbontó erős alapjaira épül. A GigaGAN több milliárd képet használ fel a nagy felbontású tartalmak eloszlásának modellezésére és a felmintavételezett képek finom részletességének létrehozására. A GigaGAN videomodellre való felfújásával és időbeli modulok beépítésével a VideoGigaGAN célja, hogy a kép-felmintavételezés sikerét kiterjessze a videófelbontás kihívást jelentő feladatára, miközben megőrzi az időbeli konzisztenciát.
A módszer áttekintése: A részletesség és a konzisztencia fokozása
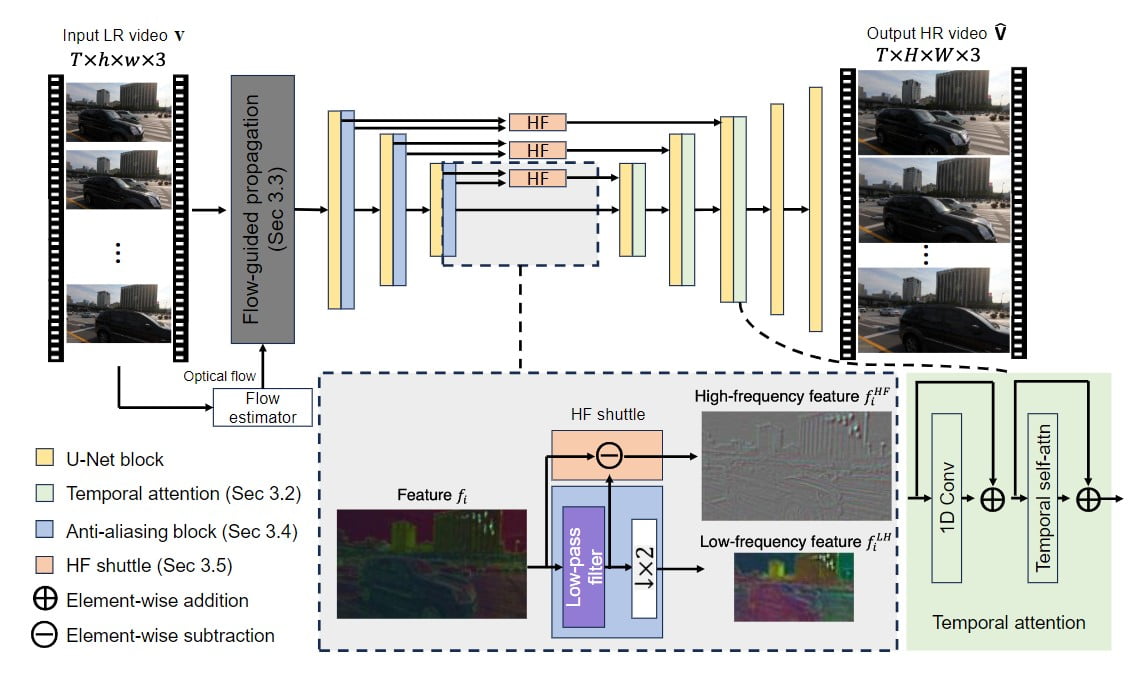
A VideoGigaGAN architektúrája az aszimmetrikus U-hálón alapul, hasonlóan a kép GigaGAN upsampleréhez. Az időbeli konzisztencia kikényszerítése érdekében azonban több kulcsfontosságú technikát vezettek be. Először is, a kép-felfelé-mintavételezőt videó-felfelé-mintavételezővé duzzasztják a dekóderblokkokba időbeli figyelemrétegek hozzáadásával. Ez biztosítja, hogy a generált képkockák időben konzisztensek legyenek.
Ezenkívül egy áramlásvezérelt terjedési modul is beépítésre került, hogy a képkockák közötti konzisztenciát fokozza az áramlási információn alapuló jellemzők összehangolásával. A lemintavételezés okozta aliasing-eltérések elnyomása érdekében a kódolóban anti-aliasing blokkok kerülnek bevezetésre. Ezenkívül a nagyfrekvenciás jellemzők közvetlenül a dekódoló rétegekbe kerülnek átugrási kapcsolatokon keresztül, hogy kompenzálják a felfelé mintavételezés során bekövetkező részletveszteséget.
Ablációs tanulmány: A villódzó műalkotások és az aliasing leküzdése
Az ablációs tanulmányban az Adobe kutatói a kép GigaGAN erős hallucinációs képességét azonosították az időbeli villódzó műalkotások, különösen az alacsony felbontású bemenetből eredő aliasing okaként. E problémák kezelése érdekében az alapmodellhez fokozatosan több komponenst adtak hozzá. Ezek a komponensek közé tartoznak az időbeli figyelemrétegek, az áramlásvezérelt jellemzőterjedés, az anti-aliasing blokkok és a nagyfrekvenciás sikló. Ezekkel a kiegészítésekkel a VideoGigaGAN figyelemre méltó egyensúlyt teremt a részletgazdag felmintavételezés és az időbeli konzisztencia között, enyhítve a korábbi megközelítéseknél megfigyelt műtermékeket és villódzást.
Összehasonlítás a legkorszerűbb módszerekkel

A VideoGigaGAN-t széles körben értékelték és összehasonlították a legkorszerűbb videós szuperfelbontási modellekkel nyilvános adathalmazokon. Az eredmények azt mutatják, hogy a VideoGigaGAN lényegesen finomabb megjelenési részletekkel rendelkező videókat generál, miközben hasonló időbeli konzisztenciát tart fenn. A GAN-ok erejének kihasználásával és innovatív technikák beépítésével a VideoGigaGAN a videó szuperfelbontás határait feszegeti, és a felskálázott videókban a realizmus és a minőség új szintjét kínálja.
Felmintavételi eredmények: Páratlan részletesség feltárása
A VideoGigaGAN egyik leglenyűgözőbb tulajdonsága, hogy képes akár 8-szoros felskálázásra is, miközben megőrzi a lenyűgöző részletességet. A modell kiválóan képes olyan nagyfrekvenciás részleteket létrehozni, amelyek az alacsony felbontású bemeneten nem voltak jelen, így a videók figyelemre méltóan valósághűek és tiszták. A felmintavételezés eredményeinek az alapigazsággal rendelkező képekkel való összehasonlításával nyilvánvaló, hogy a VideoGigaGAN a részletesség megőrzése és az általános minőség tekintetében felülmúlja a korábbi módszereket.
Pillantás a jövőbe: Általános videók és kis tárgyak kezelése
A VideoGigaGAN képességei túlmutatnak az egyes videokategóriákon. A modell lenyűgöző teljesítményt mutat a változatos tartalmú általános videók kezelésében. A rendkívül hosszú videók és a kis méretű objektumok esetében azonban továbbra is vannak kihívások. A jövőbeli kutatás az optikai áramlásbecslés javítására és az olyan kis részletek, mint a szöveg és a karakterek kezelésével kapcsolatos kihívások kezelésére összpontosíthat. E szempontok további finomításával a VideoGigaGAN még nagyobb lehetőségeket tárhat fel a videók szuperfelbontásában.
Következtetés: A videó felskálázás megváltoztatása a VideoGigaGAN-nal
Az Adobe VideoGigaGAN AI modellje jelentős előrelépést jelent a videó szuperfelbontás területén. A GAN-ok erejének kihasználásával és innovatív technikák beépítésével a VideoGigaGAN páratlan részletességet és konzisztenciát ér el a felskálázott videókban. A VideoGigaGAN akár 8-szoros felskálázásra is képes, miközben megőrzi a finom részleteket és az időbeli stabilitást, így új lehetőségeket nyit az alacsony felbontású videótartalmak feljavítására. Mivel a kiváló minőségű videók iránti igény egyre nő a különböző iparágakban, a VideoGigaGAN forradalmasíthatja a videomédia feldolgozását és fogyasztását.
Fogalommeghatározások
- Videó szuperfelbontás (VSR): Az alacsony felbontású videó nagyobb felbontásúvá alakítása a finom részletek visszanyerésével és a képkockák közötti sima átmenetek biztosításával.
- GigaGan: Az Adobe által a képek felskálázásához kifejlesztett nagy teljesítményű generatív adverzális hálózat, amely arról ismert, hogy képes jelentősen feljavítani a kép részleteit.
- VideoGigaGAN: A GigaGan videókhoz igazított kiterjesztése, amely fejlett mesterséges intelligencia technikákat használ a videók felbontásának és minőségének javítására, az időbeli konzisztencia fenntartása mellett.
- Időbeli konzisztencia a videókban: A videó egymást követő képkockáinak simasága és egyenletessége, amely biztosítja, hogy a javítások ne zavarják meg a mozgás áramlását, és ne okozzanak zavaró vizuális leleteket.
- Aszimmetrikus U-háló: A VideoGigaGAN-ban a videóadatok térbeli és időbeli dimenzióinak kezelésére adaptált neurális hálózati architektúra, amelyet olyan feladatokhoz használnak, mint a képszegmentálás.
- Korszerű módszerek: Az adott területen jelenleg elérhető legfejlettebb és leghatékonyabb technikák, amelyek gyakran mércét állítanak fel a teljesítmény és a hatékonyság tekintetében.
Gyakran ismételt kérdések
- Mi különbözteti meg az Adobe VideoGigaGAN-t a többi videó szuperfelbontó eszköztől? Az Adobe VideoGigaGAN a GAN technológia és az újszerű U-Net architektúra egyedülálló kombinációját alkalmazza, amely lehetővé teszi a videófelbontás javítását, miközben a korábbi módszerek által nem tapasztalt magas szintű részletesség és időbeli konzisztencia megőrzése mellett.
- Az Adobe VideoGigaGAN képes kezelni a gyors mozgású vagy összetett jeleneteket tartalmazó videókat? Igen, a VideoGigaGAN-t úgy tervezték, hogy különböző videótartalmakat, köztük gyors mozgást és összetett jeleneteket is kezelni tudjon, köszönhetően az áramlásvezérelt moduloknak és az időbeli figyelemrétegeknek, amelyek biztosítják a sima és részletes kimenetet.
- Milyen technikai követelmények szükségesek az Adobe VideoGigaGAN AI modell hatékony használatához? Az Adobe VideoGigaGAN AI modell használatához robusztus számítási beállításra van szükség, ideális esetben nagy teljesítményű GPU-kkal, például az NVIDIA RTX sorozatával, hogy kezelni tudja a valós idejű videók javításához szükséges intenzív feldolgozást.
- Hogyan biztosítja az Adobe VideoGigaGAN a felskálázott videók valósághűségét és minőségét? A VideoGigaGAN olyan fejlett mesterséges intelligencia-technikákat tartalmaz, mint a generatív adverzális hálózatok, az időbeli figyelem és az áramlásvezérelt terjedés a videók valósághű feljavítása érdekében, biztosítva, hogy a felskálázott videók megőrizzék a természetes textúrákat és a koherens mozgást.
- Milyen jövőbeli fejlesztések várhatók az Adobe VideoGigaGAN AI-modelljétől? A VideoGigaGAN jövőbeli verziói valószínűleg a hatékonyság javítására, a számítási igények csökkentésére és a még hosszabb videók és kisebb objektumok még pontosabb kezelésére való képességének fokozására fognak összpontosítani.