
Last Updated on augusztus 8, 2024 1:30 du. by Laszlo Szabo / NowadAIs | Published on augusztus 8, 2024 by Laszlo Szabo / NowadAIs
YI-VL-34B: A multimodális mesterséges intelligencia újradefiniálása angolul és kínaiul – Főbb megjegyzések
- Az YI-VL-34B egy kétnyelvű, angol és kínai nyelven egyaránt kiválóan beszélő látásnyelvi modell, amelyet a 01.AI fejlesztett ki.
- A modell az MMMU és a CMMMU benchmarkok élén áll, páratlan teljesítményt nyújtva a multimodális mesterséges intelligencia területén.
- A YI-VL-34B olyan platformokon keresztül érhető el, mint a Hugging Face, nyílt forráskódú erőforrásokkal a kutatók és fejlesztők számára.
Yi-VL-34B Elérhető
A 01.AI által kifejlesztettYi-VL-34B, a nyílt forráskódú látásnyelvi modell (VLM) a multimodális mesterséges intelligencia világelsőjeként jegyzi nevét. Ez a kétnyelvű, angolul és kínaiul egyaránt jól beszélő óriás 2024 januárjától az MMMU (Multimodal Multidisciplinary Multilingual Understanding) és a CMMMU (Chinese Multimodal Multidisciplinary Multilingual Understanding) benchmarkokon a létező nyílt forráskódú modellek között az áhított első helyet foglalja el.
Úttörő multimodális képességek
A Yi-VL-34B úttörő szerepet tölt be, és a multimodális intelligencia új korszakát nyitja meg. Figyelemre méltó képességei messze túlmutatnak a puszta szövegértésen, lehetővé téve a vizuális információk zökkenőmentes értelmezését és a vizuális információkról való beszélgetést. Ez az úttörő VLM könnyedén képes megérteni és elemezni a képeket, kivonva a bonyolult részleteket, és értelmes szöveges leírásokat generálva, vagy többkörös vizuális kérdés-válaszoló üléseken való részvételre.
Építészeti leleményesség: LLaVA keretrendszer
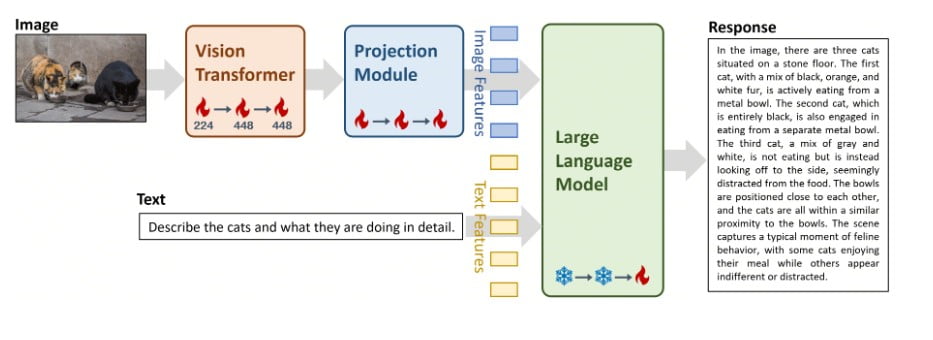

A Yi-VL-34B központi eleme a zseniális LLaVA (Large Language and Vision Assistant) architektúra, amely három kritikus komponens harmonikus fúziója:
- Vision Transformer (ViT): A legkorszerűbb CLIP ViT-H/14 modellel inicializált komponens a vizuális információk páratlan pontosságú kódolásáért felelős.
- Vetítési modul: Ez a bonyolult modul a képi és szöveges reprezentációk közötti szakadék áthidalására készült, és a vizuális jellemzőket a szöveges jellemzőtérhez igazítja, biztosítva a zökkenőmentes integrációt.
- Nagy nyelvi modell (LLM): Ez a komponens a Yi-VL-34B nyelvi képességeinek gerincét képezi, és a kivételes kétnyelvű megértési és generálási képességeiről híres, félelmetes Yi-34B-Chat modellel van inicializálva.
Átfogó képzési program
A Yi-VL-34B teljes potenciáljának kibontakoztatásához a 01.AI szigorú, háromlépcsős képzési folyamatot alkalmazott, amelyet aprólékosan a vizuális és nyelvi információknak a modell szemantikai terében való összehangolására szabtak:
- 1. szakasz: A ViT és a vetítési modul paramétereit 224×224-es képfelbontással képeztük ki, a LAION-400M korpusz 100 millió kép-szöveg párosából álló hatalmas adathalmaz felhasználásával. Ennek a kezdeti szakasznak a célja a ViT vizuális megértésének javítása és az LLM komponenssel való jobb összehangolás elérése volt.
- 2. szakasz: A képfelbontást 448×448-ra növelték, tovább finomítva a ViT és a vetítési modul paramétereit. Ez a szakasz a modellnek a bonyolult vizuális részletek felismerésére való képességének fokozására összpontosított, 25 millió kép-szöveg párosból álló változatos adathalmazból merítve, beleértve a LAION-400M, CLLaVA, LLaVAR, Flickr, VQAv2, RefCOCO, Visual7w és más képeket.
- 3. szakasz: Az utolsó szakasz a teljes modell finomhangolását jelentette, amelynek során az összes komponens (ViT, vetítési modul és LLM) tréningnek vetettük alá. Ennek a döntő fontosságú lépésnek az volt a célja, hogy a Yi-VL-34B jártasságát növelje a multimodális csevegőinterakciókban, lehetővé téve számára a vizuális és nyelvi bemenetek zökkenőmentes integrálását és értelmezését. A képzési adathalmaz körülbelül 1 millió kép-szöveg párost tartalmazott különböző forrásokból, többek között a GQA, VizWiz VQA, TextCaps, OCR-VQA, Visual Genome, LAION GPT4V és más forrásokból, az adatok kiegyensúlyozottsága érdekében az egyes források maximális hozzájárulásának felső határával.
Páratlan teljesítmény: Benchmarking fölény
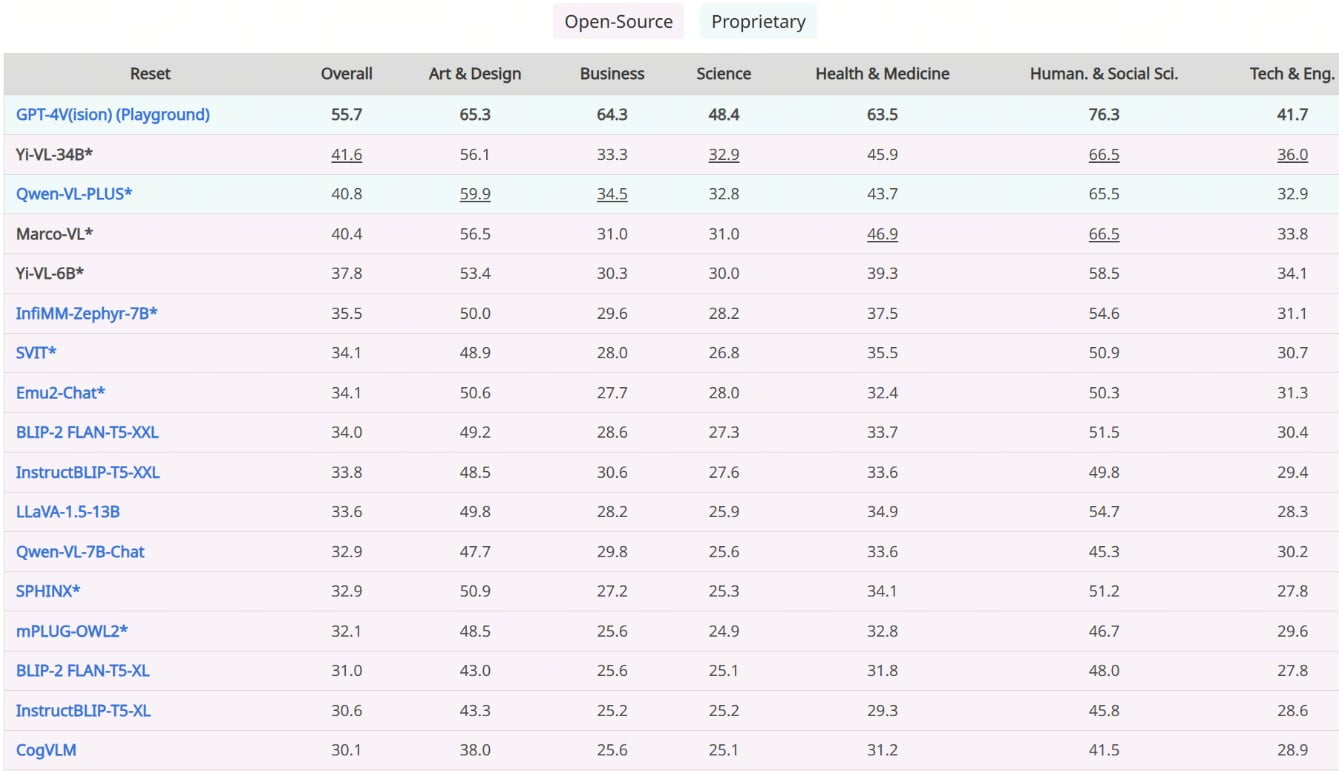
A Yi-VL-34B bátorsága a legfrissebb benchmarkokban elért páratlan teljesítményében is megmutatkozik, megszilárdítva ezzel a nyílt forráskódú VLM-ek között vitathatatlanul vezető pozícióját. Az MMMU és CMMMU benchmarkokon, amelyek számos multimodális kérdést tartalmaznak, több tudományágat felölelve, a Yi-VL-34B minden versenytársát felülmúlta, új mércét állítva a nyílt forráskódú multimodális mesterséges intelligencia terén.
A vizuális megértés bemutatása
A Yi-VL-34B figyelemre méltó vizuális megértési képességeinek illusztrálására a 01.AI megosztott egy sor lenyűgöző példát, amelyek a modell részletes leírási és vizuális kérdésmegoldási feladatokban mutatják be a modell képességeit. Ezek az angol és kínai nyelven is elérhető minták bizonyítják, hogy a modell figyelemre méltó folyékonysággal és pontossággal képes értelmezni és beszélgetni a bonyolult vizuális jelenetekről.
Különböző alkalmazások támogatása
Páratlan multimodális képességeivel a Yi-VL-34B óriási lehetőségeket rejt magában az alkalmazások széles skáláján, olyan különböző területeken, mint a számítógépes látás, a természetes nyelvi feldolgozás és a multimédia-elemzés. A képfeliratozástól és a vizuális kérdésmegoldástól a jelenetmegértésig és a multimodális következtetésig ez az úttörő VLM új határokat ígér a mesterséges intelligencia által támogatott megoldások terén.
Hozzáférhetőség és könnyű használat
A széles körű elfogadás és felfedezés elősegítése érdekében a 01.AI a Yi-VL-34B-t különböző csatornákon keresztül könnyen elérhetővé tette, beleértve a híres Hugging Face, ModelScope és wisemodel platformokat. Akár tapasztalt kutató, akár adattudós vagy AI-rajongó, a Yi-VL-34B elérhetősége és a vele való kísérletezés még sosem volt ilyen kényelmes.
Hardverkövetelmények és telepítési megfontolások
A Yi-VL-34B-ben rejlő lehetőségek teljes körű kiaknázásához a felhasználóknak meghatározott hardverkövetelményeknek kell megfelelniük. Az optimális teljesítmény érdekében a 01.AI azt javasolja, hogy a modellt nagy teljesítményű GPU-kon, például négy NVIDIA RTX 4090 GPU-n vagy egyetlen A800 GPU-n, 80 GB VRAM-mal telepítsék. Nagyon fontos, hogy a modell képességeinek maximális kiaknázásához biztosítsa, hogy a hardvere megfeleljen ezeknek a specifikációknak.
A nyílt forráskódú együttműködés felkarolása
A nyílt forráskódú innováció szellemének megfelelően a 01.AI elismerését és háláját fejezi ki a különböző nyílt forráskódú projektek fejlesztőinek és közreműködőinek, akik kulcsszerepet játszottak a Yi-VL-34B fejlesztésében. Ide tartozik a LLaVA kódbázis, az OpenCLIP és más felbecsülhetetlen értékű források, amelyek nagyban hozzájárultak a VLM kialakításához.
Felelős mesterséges intelligencia és etikai megfontolások
Bár a Yi-VL-34B jelentős előrelépést jelent a multimodális mesterséges intelligencia terén, a 01.AI felismeri az ilyen nagy teljesítményű modellekkel kapcsolatos lehetséges kockázatokat és korlátokat. A vállalat hangsúlyozza a felelős AI-gyakorlatok és etikai megfontolások fontosságát, elismerve a hallucinációk, a felbontási problémák és más ismert korlátok lehetőségét. 01.AI arra ösztönzi a felhasználókat, hogy a Yi-VL-34B alkalmazása előtt gondosan mérjék fel a potenciális kockázatokat, és a modellt felelősségteljesen, az etikai irányelvek és a legjobb adatbiztonsági gyakorlatok betartásával használják.
Előrehaladás: A multimodális intelligencia jövője
A Yi-VL-34B megjelenése jelentős mérföldkövet jelent a fejlettebb és alkalmasabb multimodális AI-rendszerek felé vezető úton. Mivel a terület továbbra is gyorsan fejlődik, a 01.AI továbbra is elkötelezett a lehetséges határok feszegetése, az együttműködés elősegítése és az innováció ösztönzése mellett a látás-nyelvi modellek területén.
A Yi-VL-34B vezetésével a multimodális intelligencia jövője fényesebbnek tűnik, mint valaha, és megnyitja az utat a vizuális és nyelvi információkat zökkenőmentesen integráló, úttörő alkalmazások és megoldások előtt. Ahogy a világ elfogadja ezt a paradigmaváltást, a Yi-VL-34B az inspiráció jelzőfénye, amely a kutatók, fejlesztők és látnokok fantáziáját egyaránt beindítja, és egy olyan jövő felé terel minket , ahol az AI túllép a határokon és a lehetőségek új birodalmait nyitja meg.
Leírások
- Multimodális mesterséges intelligencia: Olyan mesterséges intelligencia rendszer, amely többféle adatformát, például szöveget, képet és hangot integrál az információk megértéséhez és generálásához. Ez a megközelítés természetesebb és átfogóbb interakciókat tesz lehetővé az AI-modellekkel.
- Vision Language Model (VLM): A mesterséges intelligenciamodell egy olyan típusa, amelyet vizuális és szöveges adatok megértésére és generálására terveztek. A VLM-ek olyan feladatokat tudnak ellátni, mint a képfeliratozás és a vizuális kérdések megválaszolása, ami sokoldalú eszközzé teszi őket a mesterséges intelligencia kutatásában.
- LLaVA keretrendszer: A Large Language and Vision Assistant keretrendszer, amely a YI-VL-34B alapját képezi. A vizuális adatokat nyelvi megértéssel kombinálja, hogy javítsa a modell komplex információk értelmezésére és az azokkal való interakcióra való képességét.
- Vision Transformer (ViT): Egy neurális hálózati architektúra, amely a vizuális adatokat a nyelvi modellek szövegfeldolgozásához hasonló módon dolgozza fel. A YI-VL-34B-ben a vizuális információk nagy pontosságú kódolására használják.
- Vetítési modul: A YI-VL-34B egy olyan összetevője, amely a vizuális jellemzőket a szöveggel összehangolja, biztosítva, hogy a képeket és a nyelvet a mesterséges intelligencia modellje koherens módon értelmezze.
- Nagy nyelvi modell (LLM): A YI-VL-34B nyelvfeldolgozási képességeinek magja. Szöveges adatokat kezel, lehetővé téve a modell számára, hogy koherens és a kontextus szempontjából releváns válaszokat generáljon.
- Összehasonlító teljesítmény: A YI-VL-34B vezető teljesítményére utal, amely a mesterséges intelligenciamodellek multimodális és többnyelvű feladatok kezelésére vonatkozó képességeit mérő teszteken nyújtott kiemelkedő teljesítményét bizonyítja.
- Multimodális, multidiszciplináris, többnyelvű megértés (MMMU): Egy benchmark, amely egy mesterséges intelligenciamodell különböző tudományágak és nyelvek közötti jártasságát értékeli, tesztelve a különböző típusú adatok integrálásának és feldolgozásának képességét.
- Nyílt forráskódú együttműködés: A szoftverek fejlesztésének gyakorlata nyilvánosan hozzáférhető kóddal, amely lehetővé teszi, hogy bárki használhassa, módosíthassa és terjeszthesse azt. A YI-VL-34B fejlesztését olyan nyílt forráskódú erőforrások támogatták, mint a LLaVA és az OpenCLIP.
- Etikus AI-gyakorlatok: Irányelvek, amelyek biztosítják a mesterséges intelligencia felelősségteljes és etikus használatát, az átláthatóságra, a méltányosságra és a károk minimalizálására összpontosítva. A YI-VL-34B hangsúlyozza, hogy használatakor fontos betartani ezeket a gyakorlatokat.
Gyakran ismételt kérdések
- Milyen típusú gyógyszer az YI-VL-34B és hogyan működik? A YI-VL-34B egy fejlett látásnyelvi modell, amely integrálja a szöveges és vizuális adatokat, hogy összetett feladatokat hajtson végre angol és kínai nyelven egyaránt. A LLaVA keretrendszert felhasználva multimodális bemeneteket dolgoz fel, hogy pontos válaszokat és éleslátó elemzéseket generáljon.
- Hogyan teljesít az YI-VL-34B jobban más modelleknél az MMMU és CMMMU benchmarkokon? A YI-VL-34B felülmúlja a többi modellt kifinomult architektúrájának köszönhetően, amely egy Vision Transformer, egy vetítési modul és egy Large Language Model kombinációja. Ez a szinergia lehetővé teszi, hogy a multimodális és többnyelvű feladatokban is kiemelkedő teljesítményt nyújtson, új mércét állítva fel a nyílt forráskódú mesterséges intelligencia teljesítménye terén.
- Melyek a YI-VL-34B gyakorlati alkalmazásai? A YI-VL-34B alkalmazások széles skáláját kínálja, beleértve a képfeliratozást, a vizuális kérdések megválaszolását és a jelenetek megértését. A vizuális és nyelvi információk értelmezésére való képessége olyan területeken teszi értékessé, mint a számítógépes látás, a természetes nyelvi feldolgozás és a multimédia-elemzés.
- Hogyan férhetnek hozzá és használhatják a fejlesztők a YI-VL-34B-t? A fejlesztők a YI-VL-34B-hez olyan platformokon keresztül férhetnek hozzá, mint a Hugging Face, amelyek nyílt forráskódú erőforrásokat biztosítanak a modell különböző projektekbe történő integrálásához. Ez a hozzáférhetőség elősegíti az innovációt és az együttműködést a mesterséges intelligencia közösségen belül.
- Milyen etikai megfontolások merülnek fel a YI-VL-34B használatakor? A YI-VL-34B használata során alapvető fontosságú az etikus mesterséges intelligencia gyakorlatok követése, például az adatvédelem biztosítása és a modell kimeneteinek lehetséges torzításainak minimalizálása. A fejlesztőknek gondosan értékelniük kell ezeket a tényezőket a technológia felelősségteljes alkalmazásának biztosítása érdekében.







