
Last Updated on agosto 8, 2024 1:32 pm by Laszlo Szabo / NowadAIs | Published on agosto 8, 2024 by Laszlo Szabo / NowadAIs
YI-VL-34B: Redefinición de la IA multimodal en inglés y chino – Notas clave
- YI-VL-34B es un modelo lingüístico de visión bilingüe que destaca tanto en inglés como en chino, desarrollado por 01.AI.
- El modelo lidera las pruebas MMMU y CMMMU, mostrando un rendimiento sin igual en IA multimodal.
- YI-VL-34B es accesible a través de plataformas como Hugging Face, con recursos de código abierto para investigadores y desarrolladores.
Yi-VL-34B Disponible
Yi-VL-34B, el modelo de visión del lenguaje (VLM) de código abierto desarrollado por 01.AI, se ha convertido en la punta de lanza mundial en el campo de la inteligencia artificial multimodal. Este monstruo bilingüe, experto tanto en inglés como en chino, se ha asegurado el codiciado primer puesto entre todos los modelos de código abierto existentes en las pruebas MMMU (Multimodal Multidisciplinary Multilingual Understanding) y CMMMU (Chinese Multimodal Multidisciplinary Multilingual Understanding), en enero de 2024.
Proeza multimodal pionera
Yi-VL-34B es un pionero que inaugura una nueva era de inteligencia multimodal. Sus extraordinarias capacidades van mucho más allá de la mera comprensión de texto, permitiéndole interpretar y conversar a la perfección sobre información visual. Este innovador VLM puede comprender y analizar imágenes sin esfuerzo, extraer detalles intrincados y generar descripciones textuales perspicaces o participar en sesiones de preguntas visuales de varias rondas.
Ingenio arquitectónico: El marco LLaVA
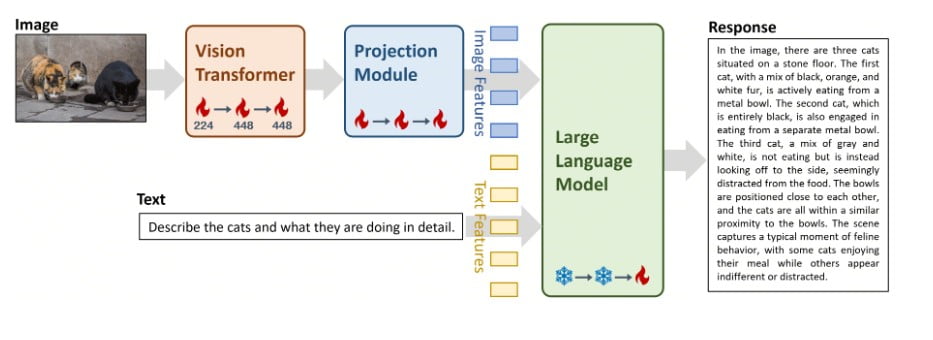

En el núcleo de Yi-VL-34B se encuentra la ingeniosa arquitectura LLaVA (Large Language and Vision Assistant), una armoniosa fusión de tres componentes críticos:
- Transformador de Visión (ViT): Inicializado con el modelo CLIP ViT-H/14 de última generación, este componente se encarga de codificar la información visual con una precisión sin precedentes.
- Módulo de proyección: Diseñado para salvar la brecha entre las representaciones de imagen y texto, este intrincado módulo alinea las características visuales con el espacio de características textuales, garantizando una integración perfecta.
- Gran modelo lingüístico (LLM): La columna vertebral de la destreza lingüística de Yi-VL-34B, este componente se inicializa con el formidable modelo Yi-34B-Chat, famoso por sus excepcionales capacidades de comprensión y generación bilingües.
Completo régimen de entrenamiento
Para liberar todo el potencial de Yi-VL-34B, 01.AI empleó un riguroso proceso de entrenamiento en tres fases, meticulosamente diseñado para alinear la información visual y lingüística dentro del espacio semántico del modelo:
- Etapa 1: Los parámetros del ViT y del módulo de proyección se entrenaron utilizando una resolución de imagen de 224×224, aprovechando un enorme conjunto de datos de 100 millones de pares imagen-texto del corpus LAION-400M. El objetivo de esta etapa inicial era mejorar la comprensión visual del ViT y lograr una mejor alineación con el componente LLM.
- Fase 2: Se aumentó la resolución de la imagen a 448×448, lo que permitió afinar aún más los parámetros del ViT y del módulo de proyección. Esta etapa se centró en aumentar la capacidad del modelo para discernir detalles visuales intrincados, a partir de un conjunto de datos diverso de 25 millones de pares imagen-texto, incluidos LAION-400M, CLLaVA, LLaVAR, Flickr, VQAv2, RefCOCO y Visual7w, entre otros.
- Etapa 3: La etapa final consistió en afinar todo el modelo, sometiendo a entrenamiento todos los componentes (ViT, módulo de proyección y LLM). Este paso crucial tenía como objetivo mejorar la competencia de Yi-VL-34B en las interacciones de chat multimodales, permitiéndole integrar e interpretar a la perfección entradas visuales y lingüísticas. El conjunto de datos de entrenamiento comprendía aproximadamente un millón de pares imagen-texto de diversas fuentes, como GQA, VizWiz VQA, TextCaps, OCR-VQA, Visual Genome y LAION GPT4V, entre otras, con un límite en la contribución máxima de cada fuente para garantizar el equilibrio de los datos.
Rendimiento sin precedentes: Supremacía en pruebas comparativas
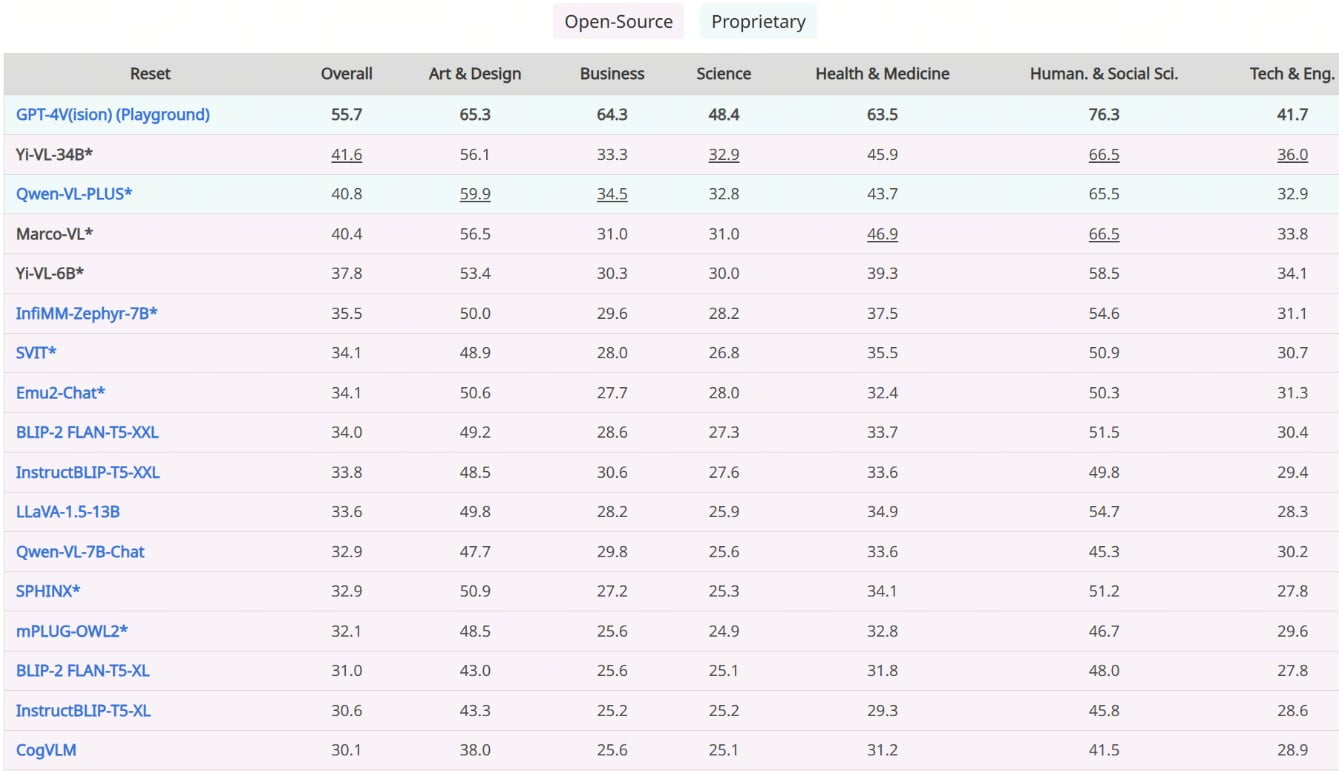
La destreza de Yi-VL-34B queda patente en su incomparable rendimiento en los últimos benchmarks, lo que consolida su posición como líder indiscutible entre los VLM de código abierto. En las pruebas MMMU y CMMMU, que abarcan una amplia gama de preguntas multimodales de múltiples disciplinas, Yi-VL-34B superó a todos los contendientes, estableciendo un nuevo estándar para la IA multimodal de código abierto.
Comprensión visual
Para ilustrar las extraordinarias capacidades de comprensión visual de Yi-VL-34B, 01.AI ha compartido una serie de ejemplos cautivadores que muestran la destreza del modelo en tareas de descripción detallada y respuesta a preguntas visuales. Estos ejemplos, disponibles tanto en inglés como en chino, sirven como testimonio de la capacidad del modelo para interpretar y conversar sobre intrincadas escenas visuales con notable fluidez y precisión.
Aplicaciones diversas
Con sus incomparables capacidades multimodales, Yi-VL-34B encierra un inmenso potencial para una amplia gama de aplicaciones, que abarcan campos tan diversos como la visión por ordenador, el procesamiento del lenguaje natural y el análisis multimedia. Desde el subtitulado de imágenes y la respuesta visual a preguntas hasta la comprensión de escenas y el razonamiento multimodal, este innovador VLM promete abrir nuevas fronteras en las soluciones basadas en IA.
Accesibilidad y facilidad de uso
Para fomentar la adopción y exploración generalizadas, 01.AI ha hecho que Yi-VL-34B esté disponible a través de varios canales, incluidas las conocidas plataformas Hugging Face, ModelScope y wisemodel. Ya sea usted un investigador experimentado, un científico de datos o un entusiasta de la IA, nunca ha sido tan cómodo acceder a Yi-VL-34B y experimentar con él.
Requisitos de hardware y consideraciones sobre la implantación
Para aprovechar todo el potencial de Yi-VL-34B, los usuarios deben cumplir unos requisitos de hardware específicos. Para obtener un rendimiento óptimo, 01.AI recomienda implantar el modelo en GPU de gama alta, como cuatro GPU NVIDIA RTX 4090 o una sola GPU A800 con 80 GB de VRAM. Es fundamental asegurarse de que el hardware cumple estas especificaciones para disfrutar al máximo de las capacidades del modelo.
Colaboración de código abierto
En consonancia con el espíritu de innovación de código abierto, 01.AI reconoce y expresa su gratitud a los desarrolladores y colaboradores de varios proyectos de código abierto que han desempeñado un papel fundamental en el desarrollo de Yi-VL-34B. Esto incluye la base de código LLaVA, OpenCLIP y otros recursos inestimables, que han sido fundamentales para dar forma a este VLM.
IA responsable y consideraciones éticas
Aunque Yi-VL-34B representa un avance significativo en la IA multimodal, 01.AI reconoce los riesgos potenciales y las limitaciones asociadas a modelos tan potentes. La empresa subraya la importancia de las prácticas de IA responsables y las consideraciones éticas, reconociendo la posibilidad de alucinaciones, problemas de resolución y otras limitaciones conocidas. 01.01.AI anima a los usuarios a evaluar cuidadosamente los riesgos potenciales antes de adoptar Yi-VL-34B y a utilizar el modelo de forma responsable, respetando las directrices éticas y las mejores prácticas de seguridad de datos.
Avanzando: El futuro de la inteligencia multimodal
El lanzamiento de Yi-VL-34B marca un hito importante en el camino hacia sistemas de IA multimodal más avanzados y capaces. A medida que este campo sigue evolucionando rápidamente, 01.AI mantiene su compromiso de ampliar los límites de lo posible, fomentar la colaboración e impulsar la innovación en el ámbito de los modelos de lenguaje visual.
Con Yi-VL-34B a la cabeza, el futuro de la inteligencia multimodal se presenta más brillante que nunca, allanando el camino para aplicaciones y soluciones revolucionarias que integren a la perfección la información visual y lingüística. A medida que el mundo abraza este cambio de paradigma, Yi-VL-34B se erige en faro de inspiración, encendiendo la imaginación de investigadores, desarrolladores y visionarios por igual, impulsándonos hacia un futuro en el que la IA trascienda fronteras y abra nuevos reinos de posibilidades.
Descripciones
- IA multimodal: un sistema de IA que integra múltiples formas de datos, como texto, imágenes y audio, para comprender y generar información. Este enfoque permite interacciones más naturales y completas con los modelos de IA.
- Modelo de lenguaje visual (VLM): Un tipo de modelo de IA diseñado para comprender y generar datos tanto visuales como textuales. Los VLM pueden realizar tareas como la subtitulación de imágenes y la respuesta a preguntas visuales, lo que los convierte en herramientas versátiles en la investigación de la IA.
- Marco LLaVA: El marco LLaVA (Large Language and Vision Assistant) es la base del YI-VL-34B. Combina los datos visuales con la comprensión del lenguaje para mejorar la capacidad del modelo de interpretar información compleja e interactuar con ella.
- Transformador de Visión (ViT): Arquitectura de red neuronal que procesa los datos visuales de forma similar a como los modelos lingüísticos procesan el texto. Se utiliza en el YI-VL-34B para codificar información visual con gran precisión.
- Módulo de proyección: Componente de YI-VL-34B que alinea las características visuales con el texto, garantizando que el modelo de IA interpreta las imágenes y el lenguaje de forma coherente.
- Gran modelo lingüístico (LLM): El núcleo de las capacidades de procesamiento lingüístico de YI-VL-34B. Maneja datos de texto, lo que permite al modelo generar respuestas coherentes y contextualmente relevantes.
- Supremacía en la evaluación comparativa: Se refiere al rendimiento líder del YI-VL-34B en pruebas que miden la capacidad de los modelos de IA para gestionar tareas multimodales y multilingües, lo que demuestra su superioridad.
- Comprensión Multilingüe Multimodal Multidisciplinar (MMMU): Un parámetro que evalúa la competencia de un modelo de IA en varias disciplinas e idiomas, poniendo a prueba su capacidad para integrar y procesar diferentes tipos de datos.
- Colaboración de código abierto: La práctica de desarrollar software con código accesible públicamente que permite a cualquiera utilizarlo, modificarlo y distribuirlo. El desarrollo de YI-VL-34B se apoyó en recursos de código abierto como LLaVA y OpenCLIP.
- Prácticas éticas de IA: Directrices que garantizan el uso responsable y ético de la IA, centrándose en la transparencia, la equidad y la minimización del daño. YI-VL-34B hace hincapié en la importancia de respetar estas prácticas durante su uso.
Preguntas más frecuentes
- ¿Qué es YI-VL-34B y cómo funciona? YI-VL-34B es un modelo lingüístico de visión avanzada que integra datos textuales y visuales para realizar tareas complejas tanto en inglés como en chino. Utilizando el marco LLaVA, procesa entradas multimodales para generar respuestas precisas y análisis perspicaces.
- ¿Cómo supera YI-VL-34B a otros modelos en las pruebas MMMU y CMMMU? YI-VL-34B supera a otros modelos gracias a su sofisticada arquitectura, que combina un transformador de visión, un módulo de proyección y un gran modelo lingüístico. Esta sinergia le permite sobresalir en tareas multimodales y multilingües, estableciendo nuevos estándares para el rendimiento de la IA de código abierto.
- ¿Cuáles son las aplicaciones prácticas de YI-VL-34B? YI-VL-34B tiene un amplio abanico de aplicaciones, entre las que se incluyen el subtitulado de imágenes, la respuesta a preguntas visuales y la comprensión de escenas. Su capacidad para interpretar información visual y lingüística lo hace valioso en campos como la visión por ordenador, el procesamiento del lenguaje natural y el análisis multimedia.
- ¿Cómo pueden los desarrolladores acceder a YI-VL-34B y utilizarlo? Los desarrolladores pueden acceder a YI-VL-34B a través de plataformas como Hugging Face, que ofrece recursos de código abierto para integrar el modelo en diversos proyectos. Esta accesibilidad fomenta la innovación y la colaboración en la comunidad de la IA.
- ¿Qué consideraciones éticas hay que tener en cuenta al utilizar YI-VL-34B? Cuando se utiliza el YI-VL-34B, es crucial seguir prácticas éticas de IA, como garantizar la privacidad de los datos y minimizar los posibles sesgos en los resultados del modelo. Los desarrolladores deben evaluar cuidadosamente estos factores para garantizar un uso responsable de la tecnología.







