Last Updated on abril 23, 2024 1:05 pm by Laszlo Szabo / NowadAIs | Published on abril 23, 2024 by Laszlo Szabo / NowadAIs
Ver lo invisible: El modelo de IA VideoGigaGAN de Adobe aporta un detalle asombroso a los vídeos borrosos – Notas clave
- El modelo VideoGigaGAN AI de Adobe mejora significativamente la resolución de los vídeos de baja resolución, garantizando detalles finos y coherencia temporal.
- Se basa en la tecnología de GigaGAN para el muestreo ascendente de imágenes, ampliada a los vídeos.
- Utiliza una arquitectura U-Net asimétrica con capas de atención temporal adicionales para mantener la coherencia entre los fotogramas.
- Supera los problemas habituales de VSR, como los parpadeos y el aliasing, con módulos avanzados como la propagación guiada por flujo.
- Demuestra un rendimiento superior en el reescalado de vídeos de hasta 8 aumentos de resolución, conservando detalles intrincados y texturas realistas.
Introducción
La superresolución de vídeo (VSR) es desde hace tiempo un reto en los campos de la visión por ordenador y los gráficos. El objetivo es mejorar la resolución de los vídeos de baja resolución, recuperando detalles finos y garantizando la coherencia temporal entre los fotogramas. Aunque los enfoques anteriores de VSR han mostrado una coherencia temporal impresionante, a menudo se quedan cortos en la generación de detalles de alta frecuencia, lo que conduce a resultados borrosos en comparación con sus homólogos de imagen.
Adobe, uno de los principales innovadores en este campo, ha presentado VideoGigaGAN, un modelo de IA generativa que aborda este reto fundamental. Basándose en el éxito de su amplificador de imágenes a gran escala, GigaGAN, VideoGigaGAN lleva la superresolución de vídeo a nuevas cotas, proporcionando vídeos con un nivel de detalle asombroso y una consistencia suave.
El reto de la superresolución de vídeo
Lograr tanto la coherencia temporal como los detalles de alta frecuencia en la superresolución de vídeo supone un reto importante. Los enfoques anteriores se han centrado en mantener la coherencia temporal utilizando redes basadas en la regresión y técnicas de alineación de flujo óptico. Aunque estos métodos garantizan transiciones suaves entre fotogramas, a menudo sacrifican la generación de apariencias detalladas y texturas realistas. Esta limitación ha motivado a los investigadores de Adobe a explorar el potencial de las redes generativas adversariales (GAN) en la superresolución de vídeo.
VideoGigaGAN: extender el éxito del sobremuestreo de imágenes a los vídeos
VideoGigaGAN parte de la sólida base de GigaGAN, un amplificador de imágenes a gran escala basado en GAN desarrollado por Adobe. GigaGAN aprovecha miles de millones de imágenes para modelar la distribución de contenidos de alta resolución y generar detalles precisos en las imágenes sobremuestreadas. Al inflar GigaGAN en un modelo de vídeo e incorporar módulos temporales, VideoGigaGAN pretende ampliar el éxito del muestreo ascendente de imágenes a la difícil tarea de la superresolución de vídeo, preservando al mismo tiempo la coherencia temporal.
Resumen del método: Mejora del detalle y la coherencia
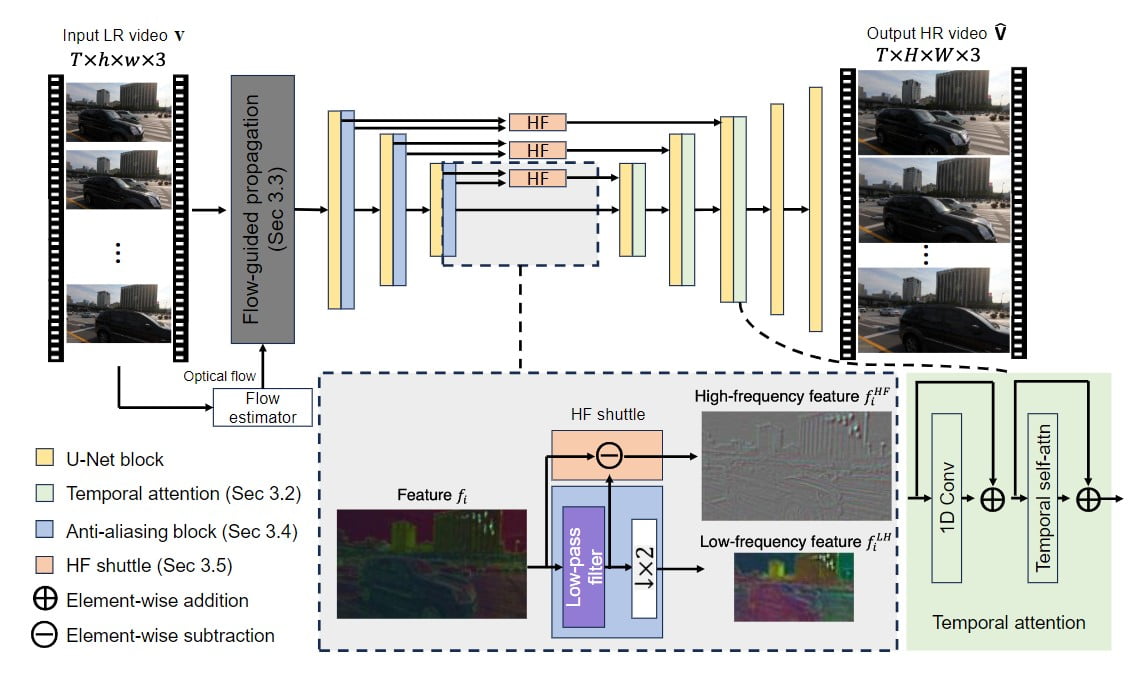
La arquitectura de VideoGigaGAN se basa en la asimétrica U-Net, similar a la imagen GigaGAN upsampler. Sin embargo, para reforzar la coherencia temporal, se han introducido varias técnicas clave. En primer lugar, el amplificador ascendente de imágenes se convierte en un amplificador ascendente de vídeo añadiendo capas de atención temporal en los bloques del descodificador. Esto garantiza que los fotogramas generados sean coherentes a lo largo del tiempo.
Además, se incorpora un módulo de propagación guiada por flujo para mejorar la coherencia entre fotogramas alineando las características en función de la información de flujo. Para suprimir los artefactos de aliasing causados por el downsampling, se introducen bloques anti-aliasing en el codificador. Además, los elementos de alta frecuencia se envían directamente a las capas del descodificador a través de conexiones de salto para compensar la pérdida de detalle durante el proceso de muestreo ascendente.
Estudio de ablación: Superación de los artefactos de parpadeo y aliasing
En el estudio de ablación, los investigadores de Adobe identificaron la gran capacidad de alucinación de la imagen GigaGAN como causa de los artefactos de parpadeo temporal, especialmente el aliasing resultante de la entrada de baja resolución. Para solucionar estos problemas, se añadieron progresivamente varios componentes al modelo base. Estos componentes incluyen capas de atención temporal, propagación de características guiada por flujo, bloques antialiasing y la lanzadera de alta frecuencia. Gracias a estas adiciones, VideoGigaGAN logra un notable equilibrio entre el aumento de la resolución y la coherencia temporal, mitigando los artefactos y el parpadeo observados en enfoques anteriores.
Comparación con los métodos más avanzados

VideoGigaGAN ha sido ampliamente evaluado y comparado con los modelos de superresolución de vídeo más avanzados en conjuntos de datos públicos. Los resultados demuestran que VideoGigaGAN genera vídeos con detalles de apariencia mucho más precisos, manteniendo al mismo tiempo una coherencia temporal comparable. Aprovechando la potencia de los GAN e incorporando técnicas innovadoras, VideoGigaGAN amplía los límites de la superresolución de vídeo, ofreciendo un nuevo nivel de realismo y calidad en los vídeos reescalados.
Resultados del sobremuestreo: Detalles sin precedentes
Uno de los aspectos más impresionantes de VideoGigaGAN es su capacidad para aumentar el tamaño de los vídeos hasta 8 veces conservando un nivel de detalle asombroso. El modelo destaca en la generación de detalles de alta frecuencia que no estaban presentes en la entrada de baja resolución, lo que da como resultado vídeos con un notable nivel de realismo y claridad. Si se comparan los resultados del muestreo con las imágenes reales, es evidente que VideoGigaGAN supera a los métodos anteriores en cuanto a conservación de los detalles y calidad general.
Una mirada al futuro: Tratamiento de vídeos genéricos y objetos pequeños
Las capacidades de VideoGigaGAN van más allá de las categorías específicas de vídeo. El modelo demuestra un rendimiento impresionante en el tratamiento de vídeos genéricos con contenidos diversos. Sin embargo, sigue habiendo problemas cuando se trata de vídeos extremadamente largos y objetos pequeños. La investigación futura puede centrarse en mejorar la estimación del flujo óptico y abordar los retos asociados al manejo de pequeños detalles como texto y caracteres. Perfeccionando estos aspectos, VideoGigaGAN tiene el potencial de abrir posibilidades aún mayores en la superresolución de vídeo.
Conclusión: Cambiando la superresolución de vídeo con VideoGigaGAN
El modelo de IA VideoGigaGAN de Adobe representa un avance significativo en el campo de la superresolución de vídeo. Al aprovechar la potencia de los GAN e incorporar técnicas innovadoras, VideoGigaGAN consigue un detalle y una coherencia sin precedentes en los vídeos reescalados. VideoGigaGAN, capaz de aumentar la resolución de los vídeos hasta 8 veces sin perder detalle ni estabilidad temporal, abre nuevas posibilidades para mejorar los contenidos de vídeo de baja resolución. Dado que la demanda de vídeo de alta calidad sigue creciendo en diversos sectores, VideoGigaGAN tiene el potencial de revolucionar la forma en que procesamos y consumimos los medios de vídeo.
Definiciones
- Superresolución de vídeo (VSR): Proceso de conversión de vídeo de baja resolución a una resolución más alta mediante la recuperación de detalles finos y la garantía de transiciones suaves de fotograma a fotograma.
- GigaGan: Una potente red generativa adversarial desarrollada por Adobe para el escalado de imágenes, conocida por su capacidad para mejorar significativamente los detalles de la imagen.
- VideoGigaGAN: una extensión de GigaGan adaptada al vídeo, que utiliza técnicas avanzadas de IA para mejorar la resolución y la calidad de los vídeos manteniendo la coherencia temporal.
- Coherencia temporal en los vídeos: La suavidad y uniformidad de los fotogramas secuenciales en un vídeo, garantizando que las mejoras no interrumpan el flujo de movimiento o introduzcan artefactos visuales discordantes.
- Red en U asimétrica: Una arquitectura de red neuronal utilizada para tareas como la segmentación de imágenes, adaptada en VideoGigaGAN para manejar las dimensiones espacial y temporal de los datos de vídeo.
- Métodos de vanguardia: Las técnicas más avanzadas y eficaces actualmente disponibles en un campo, que a menudo establecen puntos de referencia en cuanto a rendimiento y eficacia.
Preguntas más frecuentes
- ¿Qué diferencia a VideoGigaGAN de Adobe de otras herramientas de superresolución de vídeo? VideoGigaGAN de Adobe emplea una combinación única de tecnología GAN y una novedosa arquitectura U-Net, lo que le permite mejorar la resolución de vídeo a la vez que mantiene un alto nivel de detalle y una coherencia temporal sin parangón con los métodos anteriores.
- ¿Puede VideoGigaGAN de Adobe manejar vídeos con movimiento rápido o escenas complejas? Sí, VideoGigaGAN está diseñado para manejar una gran variedad de contenidos de vídeo, incluidos vídeos a cámara rápida y escenas complejas, gracias a sus módulos guiados por flujo y capas de atención temporal que garantizan unos resultados fluidos y detallados.
- ¿Cuáles son los requisitos técnicos para utilizar eficazmente el modelo VideoGigaGAN AI de Adobe? El uso del modelo VideoGigaGAN AI de Adobe requiere una configuración informática robusta, idealmente con GPU de alto rendimiento como la serie NVIDIA RTX, para manejar el procesamiento intensivo necesario para la mejora de vídeo en tiempo real.
- ¿Cómo garantiza VideoGigaGAN de Adobe el realismo y la calidad de los vídeos mejorados? VideoGigaGAN incorpora técnicas avanzadas de IA como las redes generativas adversariales, la atención temporal y la propagación guiada por flujo para mejorar los vídeos de forma realista, garantizando que los vídeos reescalados conserven las texturas naturales y el movimiento coherente.
- ¿Qué mejoras futuras cabe esperar con el modelo de IA VideoGigaGAN de Adobe? Las futuras versiones de VideoGigaGAN se centrarán probablemente en mejorar su eficacia, reducir las exigencias informáticas y mejorar su capacidad para manejar vídeos aún más largos y objetos más pequeños con mayor precisión.