
Last Updated on julio 26, 2024 12:44 pm by Laszlo Szabo / NowadAIs | Published on julio 24, 2024 by Laszlo Szabo / NowadAIs
mistral AI y NVIDIA lanzan el modelo 12B NeMo – Notas clave
- Mistral AI y NVIDIA han colaborado para crear el modelo 12B NeMo.
- NeMo cuenta con una ventana de contexto de 128.000 tokens.
- El modelo destaca en razonamiento, conocimiento general y precisión de codificación.
- NeMo está diseñado para sustituir fácilmente a Mistral 7B gracias a su arquitectura estándar.
- Disponibilidad de código abierto bajo licencia Apache 2.0 para puntos de control preentrenados.
- NeMo admite la inferencia FP8 sin pérdida de rendimiento.
- Optimizado para aplicaciones globales y multilingües.
- NeMo incluye Tekken, un tokenizador con un 30% más de eficiencia de compresión para código fuente y muchos idiomas.
NeMo AI Model por pesos pesados de la industria
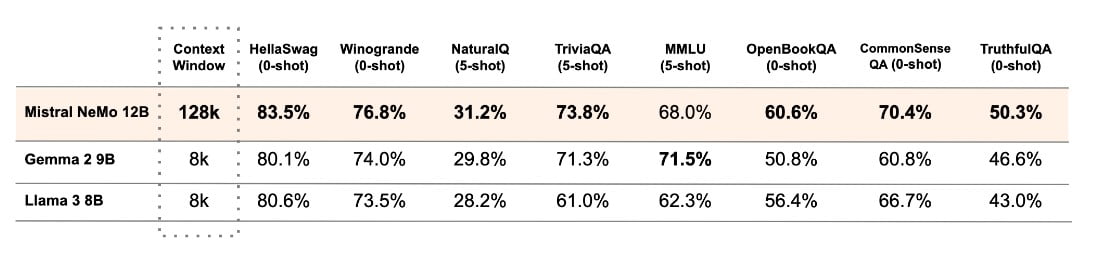
La empresa Mistral AI acaba de presentar su nuevo modelo 12B, NeMo, desarrollado en colaboración con NVIDIA. Este último modelo tiene una ventana de contexto de 128.000 tokens y se dice que consigue resultados de primera categoría en razonamiento, conocimientos generales y precisión de codificación dentro de su rango de tamaño.
La colaboración entre Mistral AI y NVIDIA ha dado lugar a un modelo que no sólo amplía los límites de su rendimiento, sino que también prioriza la comodidad. Mistral NeMo se ha creado para sustituir sin esfuerzo a los sistemas existentes que utilizan Mistral 7B, gracias a su uso de la arquitectura estándar.
Rendimiento del modelo NeMo AI

Mistral AI ha tomado recientemente la gran decisión de promover el uso y el avance de su modelo proporcionando acceso a los puntos de control preentrenados y a los puntos de control ajustados a las instrucciones bajo la licencia Apache 2.0. Se espera que este enfoque de disponibilidad de código abierto atraiga la atención tanto de investigadores como de empresas, agilizando potencialmente la integración del modelo en diversas aplicaciones.
Un aspecto clave de Mistral NeMo es su capacidad para ser consciente de la cuantificación durante el entrenamiento, lo que permite la inferencia FP8 sin sacrificar el rendimiento. Esta característica podría ser muy beneficiosa para las organizaciones que pretendan implantar eficientemente grandes modelos lingüísticos.
Mistral AI ha realizado un análisis de rendimiento del modelo base Mistral NeMo y de otros dos modelos preentrenados de código abierto, Gemma 2 9B y Llama 3 8B, y ha proporcionado una comparación entre sus rendimientos.
El rendimiento del modelo está optimizado para su uso en aplicaciones globales y multilingües. Su entrenamiento se centra en la llamada a funciones y posee una amplia ventana contextual, lo que lo hace especialmente competente en varios idiomas como inglés, francés, alemán, español, italiano, portugués, chino, japonés, coreano, árabe e hindi.
El Tekken
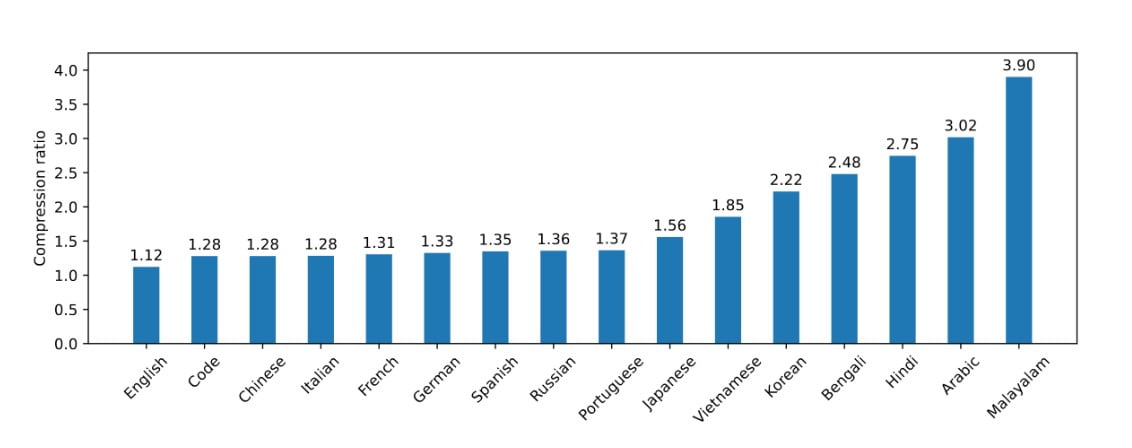
Mistral NeMo ha lanzado recientemente Tekken, un novedoso tokenizador que se basa en Tiktoken. Este nuevo tokenizador ha sido entrenado en un conjunto diverso de más de 100 idiomas. Tekken cuenta con capacidades de compresión mejoradas tanto para texto en lenguaje natural como para código fuente, superando el rendimiento del tokenizador SentencePiece utilizado en modelos anteriores de Mistral. Según la empresa, Tekken es capaz de lograr una eficacia de compresión un 30% superior para el código fuente y varios idiomas muy hablados, con mejoras aún más sustanciales para el coreano y el árabe.
Según Mistral AI, Tekken tiene un mayor rendimiento de compresión de texto en comparación con el tokenizador Llama 3 en aproximadamente el 85% de los idiomas. Esto podría proporcionar a Mistral NeMo una ventaja competitiva en aplicaciones multilingües.
Ya se puede acceder a los pesos del modelo en HuggingFace, tanto para la versión base como para las versiones con instrucciones. Los desarrolladores pueden empezar a explorar Mistral NeMo utilizando la herramienta mistral-inference y modificándola con mistral-finetune. Para los usuarios de la plataforma Mistral, el modelo puede encontrarse bajo el nombre open-mistral-nemo.
Como reconocimiento a la colaboración con NVIDIA, Mistral NeMo también se ofrece como microservicio de inferencia NIM de NVIDIA en ai.nvidia.com. Esta inclusión puede facilitar el proceso de implantación a las empresas que ya utilizan el ecosistema de IA de NVIDIA.
El lanzamiento de Mistral NeMo supone un notable avance en la puesta al alcance de todos de modelos avanzados de IA. Este modelo, desarrollado por Mistral AI y NVIDIA, ofrece alto rendimiento, capacidades multilingües y está disponible de forma abierta, lo que lo convierte en una solución versátil para una gran variedad de usos de la IA en diferentes industrias y dominios de investigación.
Definiciones
- LLM Alucinante: Cuando grandes modelos lingüísticos generan salidas plausibles pero incorrectas o sin sentido.
- HaluBench: Conjunto de datos de referencia utilizado para evaluar la precisión de los modelos de IA en la detección de alucinaciones, que abarca diversos temas del mundo real.
- Conjunto de datos PubMedQA: Conjunto de datos diseñado para evaluar modelos de IA en el ámbito de la respuesta a preguntas médicas, garantizando la precisión en contextos médicos.
- Técnica de aprendizaje automático FSDP: Fully Sharded Data Parallelism, una técnica utilizada para mejorar la eficiencia y escalabilidad del entrenamiento de grandes modelos lingüísticos mediante la distribución de datos y cálculos en múltiples GPU.
Preguntas más frecuentes
1. ¿Qué es el Modelo NeMo de Mistral AI? El Modelo NeMo de Mistral AI es un modelo de IA con 12.000 millones de parámetros desarrollado en colaboración con NVIDIA, diseñado para destacar en razonamiento, conocimientos generales y precisión de codificación.
2. ¿En qué se diferencia el Modelo NeMo de modelos anteriores como el Mistral 7B? NeMo ofrece una ventana de contexto significativamente mayor, de 128.000 tokens, y un rendimiento mejorado en razonamiento y codificación, lo que lo convierte en un sustituto superior del Mistral 7B.
3. ¿Cuáles son las principales características de NeMo? NeMo incluye una amplia ventana de contexto, compatibilidad con la inferencia FP8, capacidades multilingües y utiliza el nuevo tokenizador Tekken para mejorar la eficacia de la compresión.
4. ¿Cómo gestiona NeMo las aplicaciones multilingües? NeMo está optimizado para aplicaciones globales, soportando múltiples idiomas como inglés, francés, alemán, español, italiano, portugués, chino, japonés, coreano, árabe e hindi.
5. ¿Qué es el tokenizador Tekken y cómo mejora el rendimiento? Tekken es un nuevo tokenizador basado en Tiktoken, que ofrece un 30% más de eficacia de compresión para texto en lenguaje natural y código fuente que los tokenizadores anteriores.







