
Last Updated on Juli 30, 2024 1:19 pm by Laszlo Szabo / NowadAIs | Published on Juli 30, 2024 by Laszlo Szabo / NowadAIs
Leistung von Llama 3.1: Metas neuestes Open-Source-KI-Modell – Wichtige Hinweise
- Meta’s Llama 3.1 bietet drei Modelle: 8B, 70B, und 405B Parameter.
- Llama 3.1 erweitert die KI-Fähigkeiten um ein 128K Token-Kontextfenster und erweiterte mehrsprachige Unterstützung.
- Open-Source-Verfügbarkeit unter Apache 2.0-Lizenz.
- Signifikante Verbesserungen bei der Trainingsstabilität, der Datenqualität und der Inferenzoptimierung.
Einführung – Lernen Sie die Leistungsfähigkeit des Llama 3.1 LLM-Modells von Meta kennen
Die Veröffentlichung von Llama 3.1 durch Meta Platforms hat zweifellos Schockwellen in der Branche ausgelöst. Als neueste Iteration von Metas Open-Source-Modell für große Sprachen verspricht Llama 3.1, die Grenzen dessen, was mit KI-Technologie möglich ist, neu zu definieren. Wir befassen uns eingehend mit den Fähigkeiten, der Architektur und dem Ökosystem, das dieses bemerkenswerte Modell umgibt, und untersuchen, wie es Innovationen vorantreiben und Entwickler auf der ganzen Welt befähigen wird.
Die Llama 3.1-Familie: Unerreichte Fähigkeiten im gesamten Spektrum

Meta’s Llama 3.1 ist in drei verschiedenen Varianten erhältlich – die 8B, 70B und das Flaggschiff 405B Parameter Modelle. Jede dieser Versionen hat ihre eigenen, einzigartigen Stärken und ist für eine Vielzahl von Anwendungsfällen und Anforderungen geeignet.
Llama 3.1 8B: Ein vielseitiges Arbeitstier
Das Modell 8B ist zwar das kleinste in der Llama 3.1-Reihe, aber in Sachen Leistung kein unbeschriebenes Blatt. Mit seinen beeindruckenden Fähigkeiten in Bereichen wie Allgemeinwissen, Mathematik und Kodierung ist die 8B-Variante die ideale Wahl für Entwickler, die einen leichtgewichtigen, aber dennoch sehr leistungsfähigen KI-Assistenten suchen. Dank seiner schnellen Inferenzfähigkeiten und seines geringen Speicherbedarfs eignet er sich perfekt für den Einsatz auf einer Vielzahl von Plattformen, von Edge-Geräten bis hin zu Cloud-basierten Anwendungen.
Llama 3.1 70B: Gleichgewicht zwischen Leistung und Effizienz
Das Modell 70B bietet ein bemerkenswertes Gleichgewicht zwischen Leistung und Kosteneffizienz. Diese Variante eignet sich hervorragend für Aufgaben, die fortgeschrittene Schlussfolgerungen, mehrsprachige Kenntnisse und eine robuste Toolnutzung erfordern. Mit seiner deutlich größeren Kontextlänge von 128K und seinen hochmodernen Fähigkeiten eignet sich das Modell 70B gut für komplexe Anwendungsfälle wie die Zusammenfassung langer Texte, mehrsprachige Konversationsagenten und hochentwickelte Codierassistenten.
Llama 3.1 405B: Das Flaggschiff-Kraftpaket
Das Kronjuwel der Llama 3.1-Familie ist das Parametermodell 405B. Dieses Ungetüm ist das erste öffentlich verfügbare Modell, das es in Bezug auf Allgemeinwissen, Steuerbarkeit, Mathematik, Werkzeugnutzung und mehrsprachige Übersetzung mit den besten KI-Modellen aufnehmen kann. Seine unvergleichlichen Fähigkeiten machen es zur ersten Wahl für Entwickler, die die Grenzen dessen, was mit generativer KI möglich ist, verschieben wollen. Von der Generierung synthetischer Daten bis zur Modelldestillation eröffnet das 405B-Modell der Open-Source-Gemeinschaft eine Welt voller Möglichkeiten.
Architektonische Innovationen: Die Skalierung von Llama in neue Dimensionen

Die Entwicklung eines Modells in der Größenordnung und Komplexität von Llama 3.1 405B war keine leichte Aufgabe. Metas Team aus KI-Forschern und -Ingenieuren meisterte zahlreiche Herausforderungen, um eine wirklich erstaunliche Architektur zu schaffen.
Optimierung für das Training in großem Maßstab
Um das Training des 405B-Modells mit mehr als 15 Billionen Token zu ermöglichen, traf Meta mehrere wichtige Designentscheidungen. Sie entschieden sich für eine Standardarchitektur, die nur aus einem Decoder und einem Transformator besteht, wodurch die Trainingsstabilität gegenüber komplexeren Ansätzen bevorzugt wurde. Darüber hinaus wurde ein iteratives Post-Training-Verfahren implementiert, das die überwachte Feinabstimmung und die direkte Präferenzoptimierung nutzt, um hochwertige synthetische Daten zu erstellen und die Fähigkeiten des Modells zu verbessern.
Verbesserung von Datenqualität und -quantität
Meta erkannte die Bedeutung der Daten für die Modellleistung und investierte intensiv in die Verbesserung der Quantität und Qualität der für das Pre- und Post-Training verwendeten Daten. Dazu gehörten die Entwicklung strengerer Vorverarbeitungs- und Kuratierungspipelines sowie die Implementierung fortschrittlicher Qualitätssicherungs- und Filtertechniken.
Optimierung für Large-Scale Inference
Um die effiziente Inferenz des massiven 405B-Modells zu unterstützen, quantisierte Meta das Modell von 16-Bit (BF16) auf 8-Bit (FP8) Numerik. Durch diese Optimierung wurden die Rechenanforderungen erheblich reduziert, so dass das Modell ohne Leistungseinbußen auf einem einzigen Serverknoten ausgeführt werden kann.
Llama in Aktion: Anweisungsbefolgung und Chat-Fähigkeiten
Einer der Hauptschwerpunkte für das Llama 3.1-Entwicklungsteam war die Verbesserung der Hilfsbereitschaft, der Qualität und der detaillierten Fähigkeiten des Modells zur Befolgung von Benutzeranweisungen. Dies war eine große Herausforderung, insbesondere in Verbindung mit der größeren Modellgröße und dem erweiterten 128K-Kontextfenster.
Verbesserung der Anweisungsbefolgung
Metas Ansatz zur Verbesserung der Befehlsverfolgung umfasste mehrere Runden von Supervised Fine-Tuning (SFT), Rejection Sampling (RS) und Direct Preference Optimization (DPO). Durch den Einsatz von synthetischen Daten und rigorosen Datenverarbeitungstechniken konnte das Team die Menge der Feinabstimmungsdaten über alle Fähigkeiten hinweg skalieren und so eine hohe Qualität und Sicherheit bei allen Aufgaben gewährleisten.
Stärkung der Konversationsfähigkeiten
Neben der Befolgung von Anweisungen konzentrierte sich Meta auch auf die Verbesserung der Chat-Fähigkeiten der Llama 3.1-Modelle. Durch eine Kombination aus SFT, RS und DPO entwickelte das Team endgültige Chat-Modelle, die ein hohes Maß an Hilfsbereitschaft, Qualität und Sicherheit bieten, selbst wenn die Modelle an Größe und Komplexität zunehmen.
Das Llama-Ökosystem: Neue Möglichkeiten freisetzen
Metas Vision für Llama 3.1 geht über die Modelle selbst hinaus und umfasst ein breiteres System, das Entwicklern die Möglichkeit gibt, individuelle Angebote zu erstellen und neue Arbeitsabläufe zu erschließen.
Das Llama-System: Orchestrierung von Komponenten
Llama-Modelle wurden so konzipiert, dass sie als Teil eines größeren Systems funktionieren, das externe Tools und Komponenten einbezieht. Diese “Llama-System”-Vision beinhaltet die Veröffentlichung eines vollständigen Referenzsystems mit Beispielanwendungen und neuen Komponenten wie Llama Guard 3 (ein mehrsprachiges Sicherheitsmodell) und Prompt Guard (ein Prompt-Injection-Filter).
Definition des Llama-Stapels
Um das Wachstum des Llama-Ökosystems zu unterstützen, hat Meta den “Llama Stack” eingeführt – eine Reihe von standardisierten und abgestimmten Schnittstellen für die Erstellung von kanonischen Toolchain-Komponenten (Feinabstimmung, Erzeugung synthetischer Daten) und agentenbasierten Anwendungen. Ziel ist es, die Interoperabilität und Übernahme durch die Open-Source-Gemeinschaft zu erleichtern.
Stärkung der Entwicklergemeinschaft
Indem Meta die Gewichte des Llama-Modells offen zum Download zur Verfügung stellt, können Entwickler die Modelle vollständig an ihre individuellen Bedürfnisse und Anwendungen anpassen. Dazu gehört auch die Möglichkeit, auf neuen Datensätzen zu trainieren, zusätzliche Feinabstimmungen vorzunehmen und die Modelle in jeder beliebigen Umgebung laufen zu lassen – und das alles, ohne Daten mit Meta teilen zu müssen.
Benchmarking Llama 3.1: Wettbewerbsfähig auf der ganzen Linie
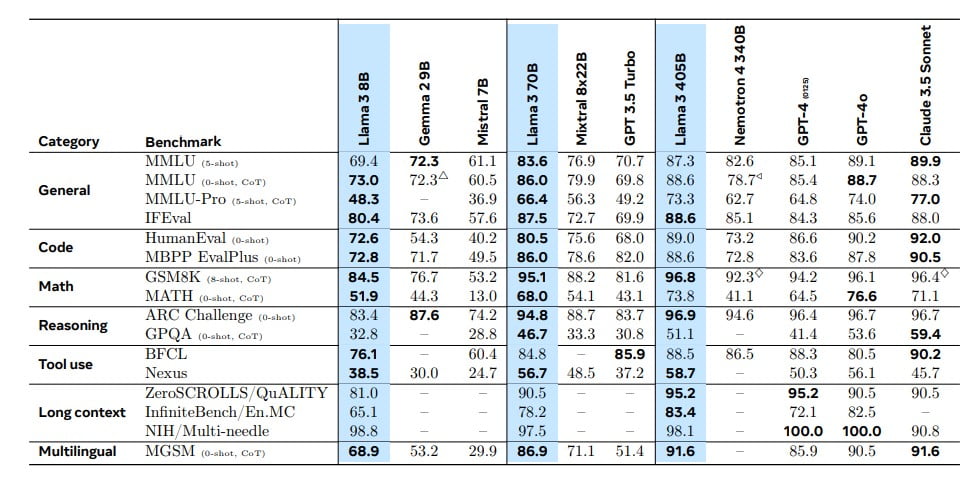
Metas Engagement für eine strenge Bewertung und ein Benchmarking der Llama 3.1-Modelle ist ein Beweis für das Vertrauen in die Fähigkeiten dieser KI-Systeme.
Umfassende Evaluierungen in verschiedenen Domänen
Für diese Version hat Meta die Leistung von Llama 3.1 anhand von über 150 Benchmark-Datensätzen bewertet, die ein breites Spektrum an Sprachen und Aufgaben abdecken. Darüber hinaus wurden umfangreiche Bewertungen durch Menschen durchgeführt, bei denen die Leistung der Modelle mit führenden Basismodellen wie GPT-4, GPT-4o und Claude 3.5 Sonnet in realen Szenarien verglichen wurde.
Wettbewerbsfähige Leistung auf der ganzen Linie
Die Ergebnisse dieser Bewertungen sind mehr als beeindruckend. Die experimentellen Daten von Meta deuten darauf hin, dass das Flaggschiffmodell Llama 3.1 in einer Vielzahl von Aufgaben, darunter Allgemeinwissen, Mathematik, logisches Denken und mehrsprachige Fähigkeiten, mit den besten KI-Modellen konkurrieren kann. Selbst die kleineren Varianten 8B und 70B haben bewiesen, dass sie mit geschlossenen und Open-Source-Modellen ähnlicher Größe mithalten können.
Preisgestaltung und Einsatzoptionen: Maximierung von Wert und Zugänglichkeit
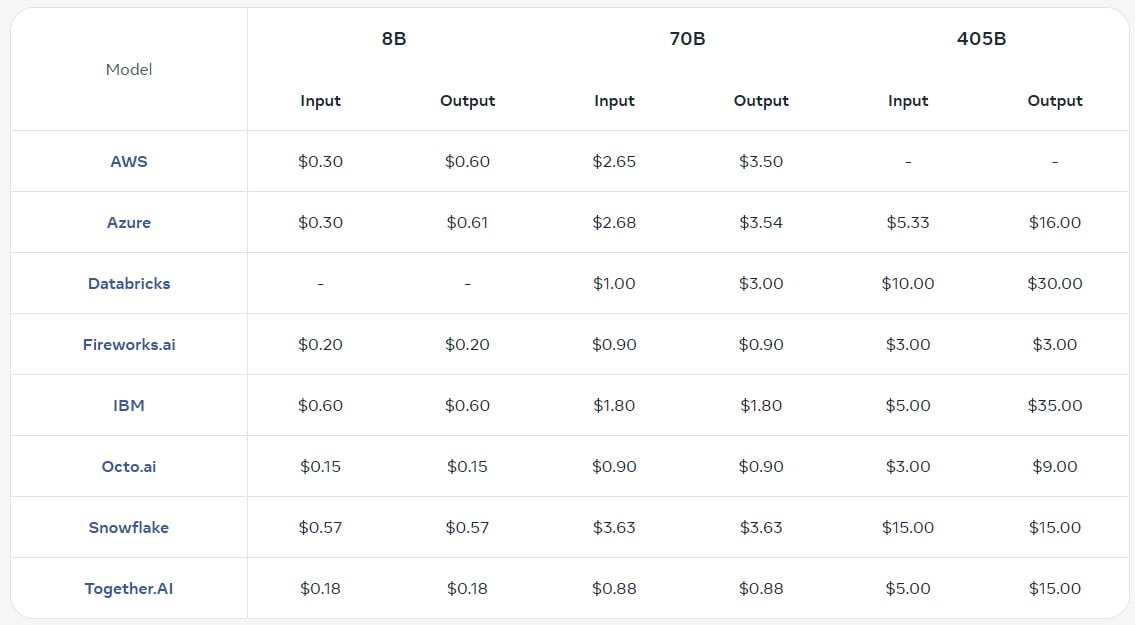
Während Entwickler und Unternehmen das Potenzial von Llama 3.1 erkunden, wird die Frage der Preisgestaltung und der Bereitstellungsoptionen entscheidend. Meta hat eng mit seinen Partnern zusammengearbeitet, um sicherzustellen, dass Llama 3.1 sowohl kosteneffizient als auch allgemein zugänglich ist.
Wettbewerbsfähige Preisgestaltung über alle Anbieter hinweg
Meta hat detaillierte Preisinformationen für gehostete Llama 3.1 Inferenz-API-Dienste veröffentlicht, die die Konkurrenzsituation zwischen verschiedenen Cloud-Anbietern und Plattformpartnern aufzeigen. Diese Transparenz ermöglicht es Entwicklern, fundierte Entscheidungen zu treffen und ihre Bereitstellungsstrategien auf der Grundlage ihrer spezifischen Bedürfnisse und Budgets zu optimieren.
Flexible Bereitstellungsoptionen
Zusätzlich zu den gehosteten Inferenzdiensten können Llama 3.1-Modelle auch kostenlos heruntergeladen und lokal bereitgestellt werden, was Entwicklern die Freiheit gibt, die Modelle in ihrer bevorzugten Umgebung einzusetzen.
“Getreu unserer Verpflichtung zu Open Source stellen wir diese Modelle ab heute der Community zum Download auf llama.meta.com und Hugging Face zur Verfügung und bieten sie zur sofortigen Entwicklung auf unserem breiten Ökosystem von Partnerplattformen an”
Erklärte Meta. Diese Flexibilität in Verbindung mit dem Open-Source-Charakter der Modelle gibt der Community die Möglichkeit, zu forschen und zu innovieren, ohne durch eine zentralisierte Infrastruktur oder Anforderungen an die gemeinsame Nutzung von Daten eingeschränkt zu werden.
Die Auswirkungen von Llama 3.1: Veränderung der KI-Landschaft
Die Veröffentlichung von Llama 3.1 wird einen tiefgreifenden und weitreichenden Einfluss auf die KI-Branche und darüber hinaus haben. Indem Meta diese leistungsstarken Modelle offen zugänglich macht, ebnet es den Weg für eine neue Ära der Innovation und Demokratisierung der KI-Technologie.
Open-Source-Fortschritte vorantreiben
Der Open-Source-Charakter von Llama 3.1 ermöglicht es Entwicklern und Forschern, die Modelle vollständig anzupassen und zu erweitern, neue Anwendungsfälle zu erschließen und die Grenzen dessen, was mit generativer KI möglich ist, zu verschieben. Dieser kollaborative Ansatz fördert eine Kultur der Innovation und des schnellen Fortschritts, von der die gesamte KI-Gemeinschaft profitiert.
Demokratisierung von KI-Fähigkeiten
Durch die Beseitigung von Zugangsbarrieren und die Ermächtigung von Entwicklern auf der ganzen Welt demokratisiert Llama 3.1 die Macht der KI. Dies steht im Einklang mit Metas Vision, die Vorteile und Möglichkeiten der KI-Technologie gleichmäßiger über die Gesellschaft zu verteilen, anstatt sie in den Händen einiger weniger zu konzentrieren.
Förderung einer verantwortungsvollen KI-Entwicklung
Neben den technischen Fortschritten legt Meta auch großen Wert auf eine verantwortungsvolle KI-Entwicklung. Das Llama-System umfasst Sicherheitsmaßnahmen wie Llama Guard 3 und Prompt Guard und zeigt damit, dass man sich der Entwicklung von KI-Systemen verschrieben hat, die nicht nur leistungsfähig, sondern auch ethisch vertretbar und vertrauenswürdig sind.
Die Zukunft von Llama: Unendliche Möglichkeiten
So beeindruckend Llama 3.1 auch sein mag, Metas Vision für die Zukunft dieses KI-Modells ist noch ehrgeiziger. Das Unternehmen ist bereits dabei, neue Grenzen zu erforschen, um den Weg für noch größere Fortschritte in den kommenden Jahren zu ebnen.
Erweiterung der Modellfähigkeiten
Während die aktuellen Llama 3.1-Modelle bereits ein breites Spektrum an Aufgaben bewältigen, ist Meta bestrebt, ihre Fähigkeiten weiter auszubauen. Dazu gehören die Erforschung gerätefreundlicherer Modellgrößen, die Einbeziehung zusätzlicher Modalitäten und umfangreiche Investitionen in die Agentenplattform, um noch ausgefeiltere und agentenbasierte Verhaltensweisen zu ermöglichen.
Wachstum des Ökosystems
Das Llama-Ökosystem ist für ein exponentielles Wachstum bereit, wobei Meta aktiv mit einer Vielzahl von Partnern zusammenarbeitet, um die unterstützende Infrastruktur, die Werkzeuge und die Dienste zu entwickeln. Durch die Förderung dieses kollaborativen Umfelds will das Unternehmen die Einstiegshürden senken und Entwickler in die Lage versetzen, innovative Anwendungen zu entwickeln, die das volle Potenzial von Llama ausschöpfen.
Zementierung der Open-Source-Führerschaft
Durch die kontinuierliche Entwicklung und Verfeinerung von Llama festigt Meta seine Position als Marktführer im Bereich der Open-Source-KI. Indem das Unternehmen neue Maßstäbe für Leistung, Skalierbarkeit und verantwortungsvolle Entwicklung setzt, ebnet es den Weg für eine Zukunft, in der Open-Source-KI-Modelle zum Industriestandard werden und weit verbreitete Innovation und Zugänglichkeit fördern.
Schlussfolgerung: Umarmung der Lama-Revolution
Die Veröffentlichung von Llama 3.1 stellt einen entscheidenden Moment in der Entwicklung der künstlichen Intelligenz dar. Durch die Veröffentlichung dieses Modells hat Meta Entwicklern, Forschern und Innovatoren auf der ganzen Welt die Möglichkeit gegeben, die Grenzen dessen zu erweitern, was mit generativer KI möglich ist. Von der Generierung synthetischer Daten bis hin zur Destillation von Modellen bietet die Llama 3.1-Sammlung unvergleichliche Möglichkeiten, die die Industrie verändern und neue Grenzen der Zusammenarbeit zwischen Mensch und Maschine eröffnen werden.
Je weiter das Llama-Ökosystem wächst und sich weiterentwickelt, desto tiefgreifender werden die Auswirkungen dieser Open-Source-Revolution sein. Durch die Förderung eines kollaborativen, transparenten und verantwortungsvollen Ansatzes bei der KI-Entwicklung ebnet Meta den Weg für eine Zukunft, in der die Vorteile fortschrittlicher KI-Technologie für alle zugänglich sind.
Machen Sie sich die Llama-Revolution zu eigen und probieren Sie sie aus – oder lesen Sie das ausführliche Forschungspapier!
Beschreibungen
LLM Halluzinieren: Fälle, in denen große Sprachmodelle falsche oder erfundene Informationen erzeugen.
HaluBench: Ein Benchmark-Datensatz, der zur Bewertung der Genauigkeit von KI-Modellen bei der Erkennung von Halluzinationen verwendet wird.
PubMedQA-Datensatz: Ein Datensatz zur Bewertung von KI-Modellen im Bereich der Beantwortung von medizinischen Fragen.
FSDP-Maschinenlerntechnik: Fully Sharded Data Parallelism, eine Technik zur Verbesserung der Effizienz und Skalierbarkeit des Trainings großer Sprachmodelle durch die Verteilung von Daten und Berechnungen auf mehrere GPUs.
Kontext-Fenster: Die Textmenge, die ein KI-Modell in einer einzigen Sitzung verarbeiten kann. Das Kontextfenster von Llama 3.1 beträgt 128K Token, was längere und detailliertere Unterhaltungen ermöglicht.
Quantisierung: Der Prozess der Reduzierung der Anzahl von Bits, die Daten repräsentieren, in diesem Fall die Konvertierung von numerischen Modelldaten von 16-Bit auf 8-Bit, um die Leistung zu optimieren, ohne die Qualität zu beeinträchtigen.
Überwachtes Fine-Tuning (SFT): Eine Trainingsmethode, bei der ein Modell anhand von markierten Daten für eine bestimmte Aufgabe feinabgestimmt wird, um seine Leistung zu verbessern.
Direkte Präferenz-Optimierung (DPO): Eine Technik, bei der das Modell direkt auf der Grundlage von Benutzerpräferenzen optimiert wird, um die Qualität der Ausgabe zu verbessern.
Prompt-Injektionsfilter: Eine Sicherheitsfunktion, die verhindert, dass bösartige Prompts die Ausgabe des Modells beeinträchtigen.
Llama-Stapel: Eine Reihe von standardisierten Schnittstellen für die Erstellung und den Einsatz von KI-Anwendungen mit Llama-Modellen.
Häufig gestellte Fragen
1. Was ist Meta’s Llama 3.1? Meta’s Llama 3.1 ist die neueste Version von Metas Open-Source-Sprachmodell. Es wurde entwickelt, um die Grenzen der KI-Technologie mit fortschrittlichen Fähigkeiten in den Bereichen Allgemeinwissen, Schlussfolgerungen und mehrsprachige Unterstützung zu erweitern.
2. Wie ist das 405B-Parameter-Modell von Llama 3.1 im Vergleich zu anderen Modellen? Das 405B-Parametermodell ist das Flaggschiff der Llama 3.1-Familie und bietet unübertroffene Fähigkeiten in den Bereichen Allgemeinwissen, Steuerbarkeit und Werkzeugnutzung. Es konkurriert in seiner Leistung mit den besten AI-Modellen und ist für die anspruchsvollsten Anwendungen konzipiert.
3. Welche Verbesserungen bietet Llama 3.1 gegenüber seinen Vorgängern? Llama 3.1 verfügt über ein deutlich größeres Kontextfenster (128K Token), verbesserte Trainingsstabilität und verbesserte Datenqualität. Diese Verbesserungen führen zu einer besseren Leistung, insbesondere bei komplexen Aufgaben, die fortgeschrittenes logisches Denken und mehrsprachige Fähigkeiten erfordern.
4. Wie gewährleistet Meta die ethische Verwendung von Llama 3.1? Meta hat Sicherheitsmaßnahmen wie den Llama Guard 3 und den Prompt Guard in das Llama-System integriert. Diese Funktionen tragen dazu bei, Missbrauch zu verhindern und sicherzustellen, dass die KI innerhalb ethischer Grenzen arbeitet und vertrauenswürdige und genaue Informationen liefert.
5. Wie können Entwickler auf Llama 3.1 zugreifen und es nutzen? Llama 3.1 steht auf der Website von Meta und Hugging Face unter der Apache 2.0 Lizenz zum Download bereit. Entwickler können die Modelle an ihre individuellen Bedürfnisse anpassen, mit neuen Datensätzen trainieren und sie in verschiedenen Umgebungen einsetzen, ohne Daten mit Meta zu teilen.







