Last Updated on August 12, 2024 1:08 pm by Laszlo Szabo / NowadAIs | Published on August 12, 2024 by Laszlo Szabo / NowadAIs
Auf Wiedersehen, rundenbasierte KI: Hallo Sprachmodell des Zuhörens beim Sprechen – Wichtige Hinweise
- Das Listening-While-Speaking Language Model (LSLM) integriert Zuhören und Sprechen in Echtzeit und beseitigt damit die Beschränkungen von rundenbasierten Dialogsystemen.
- LSLM wurde von der Shanghai Jiao Tong University und ByteDance entwickelt und verwendet eine Zweikanalarchitektur, die Token-basiertes TTS und Streaming-SSL-Encoder kombiniert.
- LSLM geht effizient mit Unterbrechungen und Hintergrundgeräuschen um und beweist in verschiedenen experimentellen Umgebungen Robustheit und Sensibilität.
- Die Middle-Fusion-Strategie optimiert die Interaktion durch die Zusammenführung von Hör- und Sprechkanälen in jedem Transformer-Block und gewährleistet so ein nahtloses Dialogerlebnis.
Einführung
In der Landschaft der Mensch-Computer-Interaktion (HCI) ist das Streben nach einer natürlicheren und intuitiveren Kommunikation eine treibende Kraft hinter technologischen Fortschritten gewesen. Als die grundlegendste Form der menschlichen Interaktion ist der Dialog seit langem der heilige Gral für KI-Systeme im Dialog. Jüngste Durchbrüche auf dem Gebiet der Sprachmodelle (SLMs) haben zweifellos die Fähigkeiten sprachbasierter KI-Systeme verbessert, doch sind diese Systeme nach wie vor durch ihren rundenbasierten Charakter eingeschränkt, da sie nicht in der Lage sind, in Echtzeit und ohne Unterbrechung zu interagieren.
Diese Einschränkung hat dazu geführt, dass die Erforschung der Vollduplexmodellierung (FDM) in interaktiven Sprachmodellen (iSLM) wieder in den Mittelpunkt gerückt ist, wobei die Forscher versuchen, die wesentliche Fähigkeit der Unterbrechung und der nahtlosen Hin- und Her-Kommunikation zu erschließen. Mitten in diesem Bestreben ist eine neue Innovation entstanden: das Listening-While-Speaking Language Model (LSLM), ein durchgängiges System, das die Art und Weise, wie Menschen und Maschinen sich unterhalten, aktualisieren soll.
Die Grenzen der rundenbasierten Dialogsysteme
Herkömmliche sprachbasierte Modelle beruhen in der Regel auf einem rundenbasierten Ansatz, bei dem Hören und Sprechen in isolierten Phasen stattfinden. Diese isolierte Struktur, die oft getrennte Module für automatische Spracherkennung (ASR) und Text-to-Speech (TTS) umfasst, hat zu inhärenten Latenzproblemen und zur Unfähigkeit geführt, Unterbrechungen in Echtzeit effektiv zu bewältigen. Bemerkenswerte Modelle wie SpeechGPT und LauraGPT haben die Grenzen der konversationellen KI erweitert, aber sie bleiben auf diese rundenbasierten Paradigmen beschränkt und bieten nicht die flüssige Interaktion, die für einen wirklich natürlichen Dialog zwischen Mensch und Computer erforderlich ist.

Die Geburt der LSLM: Überbrückung der Lücke in der Echtzeit-Interaktion
Ein Team von Forschern der Shanghai Jiao Tong University und ByteDance erkannte den Bedarf an einer nahtloseren und reaktionsfähigeren Konversationserfahrung und stellte das Listening-While-Speaking Language Model (LSLM) vor. Dieses Modell zielt darauf ab, die Einschränkungen von rundenbasierten Systemen zu überwinden, indem es sowohl Hör- als auch Sprechfunktionen in eine einzige, durchgängige Architektur integriert.
Der zweikanalige Ansatz des LSLM
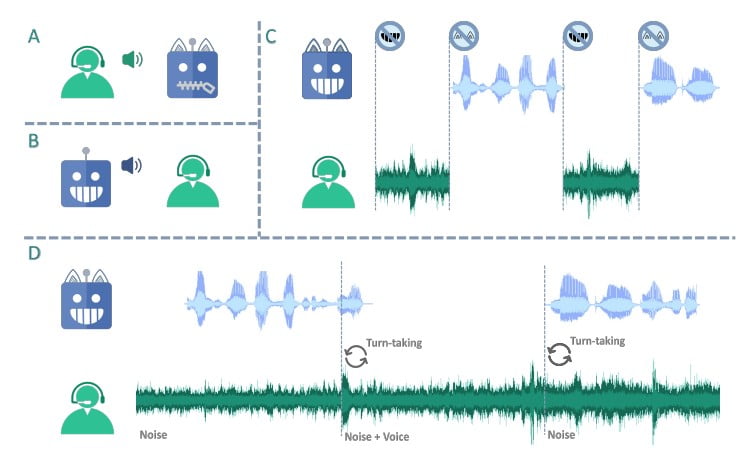
Das einzigartige Design des LSLM beruht auf seiner zweikanaligen Architektur, die einen Token-basierten Decoder für die Spracherzeugung und einen Streaming-Self-Supervised-Learning-Encoder (SSL) für die Echtzeit-Audioeingabe kombiniert. Dieser Ansatz ermöglicht es dem Modell, die Hör- und Sprechkanäle zu verschmelzen, so dass es das Abbiegen in Echtzeit erkennen und dynamisch auf die Eingaben des Benutzers reagieren kann.
Der sprechende Kanal: Autoregressive Token-basierte TTS
Im Gegensatz zu früheren Modellen, die sich auf autoregressive und nicht-autoregressive Ansätze stützten, vereinfacht die LSLM den Spracherzeugungsprozess durch die Verwendung eines Token-basierten TTS-Systems. Dadurch kann sich das Modell stärker auf semantische Informationen konzentrieren, was die Klarheit und Relevanz seiner Antworten verbessert und gleichzeitig die Interaktion in Echtzeit fördert, da eine umfangreiche Vorverarbeitung vor der Sprachsynthese entfällt.
Der Abhörkanal: Streaming-SSL-Encoder
Auf der Hörseite setzt die LSLM einen Streaming-SSL-Encoder ein, um eingehende Audiosignale kontinuierlich zu verarbeiten. Dieser Encoder wandelt den Audio-Input in kontinuierliche Einbettungen um, die dann in einen Raum projiziert werden, der nahtlos mit den gesprochenen Token integriert werden kann. Durch diese Integration wird sichergestellt, dass das Modell die Informationen beider Kanäle während des gesamten Spracherzeugungsprozesses nutzen kann.
Fusions-Strategien: Gleichgewicht zwischen Echtzeit-Interaktion und Spracherzeugung
Um die Synergie zwischen dem Hör- und dem Sprechkanal zu optimieren, untersuchten die Forscher drei Fusionsstrategien: frühe Fusion, mittlere Fusion und späte Fusion. Nach einer sorgfältigen Bewertung erwies sich der mittlere Fusionsansatz als der effektivste, da er ein optimales Gleichgewicht zwischen Echtzeit-Interaktion und Spracherzeugung herstellt.
Bei der mittleren Fusionsmethode werden die Hör- und Sprechkanäle in jedem Transformer-Block zusammengeführt, so dass das Modell die Erkenntnisse aus beiden Kanälen während des Spracherzeugungsprozesses kontinuierlich nutzen kann. Diese Integration stellt sicher, dass die LSLM mit Unterbrechungen reibungslos umgehen kann und einen kohärenten und reaktionsfähigen Dialogfluss aufrechterhält, der sich in Echtzeit an die Eingaben des Benutzers anpasst.
Evaluierung der Leistung der LSLM: Robustheit und Empfindlichkeit
Die Fähigkeiten der LSLM wurden in zwei Versuchsanordnungen getestet: befehlsbasiertes FDM und sprachbasiertes FDM. Im befehlsbasierten Szenario zeigte das Modell seine Robustheit gegenüber Hintergrundgeräuschen und reagierte effektiv auf bestimmte Befehle in einer lauten Umgebung. Im sprachbasierten Szenario hingegen wurde die Empfindlichkeit der LSLM gegenüber Unterbrechungen durch verschiedene Sprecher bewertet, wobei die Fähigkeit zur Erkennung und Anpassung an neue Stimmen und Anweisungen unter Beweis gestellt wurde.
Die Ergebnisse dieser Experimente zeigen die beeindruckende Leistung der LSLM und unterstreichen ihr Potenzial, den Bereich der interaktiven Sprachmodelle zu revolutionieren. Insbesondere die mittlere Fusionsstrategie erwies sich als entscheidender Faktor, um die Anforderungen der Echtzeit-Interaktion und der Spracherzeugung in Einklang zu bringen und eine nahtlose und reaktionsschnelle Benutzererfahrung zu bieten.
Die Grenzen der konversationellen KI verschieben
Das Listening-While-Speaking Language Model (LSLM) stellt einen bedeutenden Fortschritt auf dem Gebiet der interaktiven Sprachmodelle dar. Durch die Überwindung der Einschränkungen von rundenbasierten Systemen und die Einführung einer robusten Echtzeit-Interaktionsfähigkeit ebnet das LSLM den Weg für natürlichere und flüssigere Dialoge zwischen Mensch und Computer. Diese Forschungsarbeit unterstreicht die Bedeutung der Integration von Vollduplex-Fähigkeiten in SLMs und zeigt, wie solche Fortschritte die Anwendbarkeit von konversationeller KI in realen Szenarien verbessern können.
Schlussfolgerung: Das volle Potenzial der konversationellen KI ausschöpfen
Das Listening-While-Speaking Language Model (LSLM) stellt einen revolutionären Durchbruch im Bereich der interaktiven Sprachmodelle dar. Durch die nahtlose Integration von Hör- und Sprechfähigkeiten überwindet dieses Design die Beschränkungen traditioneller rundenbasierter Systeme und läutet eine neue Ära des natürlicheren und flüssigeren Dialogs zwischen Mensch und Computer ein. Da die Nachfrage nach intuitiven und reaktionsschnellen KI-Konversationen weiter steigt, ist die LSLM dank ihrer Fähigkeit, Echtzeit-Interaktionen zu ermöglichen und Unterbrechungen problemlos zu bewältigen, ein Wegbereiter für eine wirklich nahtlose Kommunikation zwischen Mensch und KI.
Beschreibungen
- Vollduplex-Modellierung (FDM): Ein Kommunikationssystem, bei dem beide Parteien gleichzeitig sprechen und zuhören können, im Gegensatz zu rundenbasierten Modellen, bei denen eine Partei darauf warten muss, dass die andere zu Ende spricht.
- Token-Based Decoder-Only TTS: Ein System, das Token oder Datenbits verwendet, um Sprache zu erzeugen, so dass die KI schneller und genauer reagieren kann, indem sie sich auf die Bedeutung konzentriert, anstatt umfangreiche Daten vorzuverarbeiten.
- Streaming Self-Supervised Learning (SSL) Encoder: Eine Art von KI, die Audioeingaben kontinuierlich verarbeitet und Geräusche in Daten umwandelt, die vom Modell verstanden und für die Echtzeitinteraktion verwendet werden können.
- Transformer Block: Eine Komponente in KI-Modellen, die bei der Verarbeitung und dem Verständnis von Sprache hilft, indem sie sich auf verschiedene Teile der Eingabedaten gleichzeitig konzentriert und so die Geschwindigkeit und Genauigkeit verbessert.
- Fusions-Strategien: Techniken, mit denen Daten aus verschiedenen Kanälen in ein KI-Modell integriert werden. Frühe, mittlere und späte Fusionsstrategien bestimmen, wie und wann Daten während der Verarbeitung kombiniert werden, um die Leistung zu optimieren.
- Befehlsbasiertes FDM: Ein Versuchsaufbau, bei dem das KI-Modell auf bestimmte Sprachbefehle reagiert, um seine Fähigkeit zu testen, inmitten von Hintergrundgeräuschen und Unterbrechungen zu arbeiten.
- Sprachbasiertes FDM: Ein experimentelles Szenario, in dem untersucht wird, wie gut die KI mit verschiedenen Stimmen und Unterbrechungen umgehen kann, und in dem ihre Anpassungsfähigkeit an neue Sprecher und Anweisungen bewertet wird.
Häufig gestellte Fragen
- Was ist das Listening-While-Speaking Language Model (LSLM)? Das Listening-While-Speaking Language Model (LSLM) ist ein fortschrittliches KI-System, das durch die Integration von Hör- und Sprechfähigkeiten einen Dialog in Echtzeit ermöglicht. Im Gegensatz zu herkömmlichen Modellen ermöglicht es eine nahtlose Hin- und Her-Kommunikation, ohne dass man sich umdrehen muss.
- Wie geht die LSLM mit Unterbrechungen während eines Gesprächs um? Die LSLM verwendet eine Zweikanal-Architektur mit einem Streaming-SSL-Encoder, der den Audio-Input kontinuierlich verarbeitet. Dadurch kann sie Unterbrechungen problemlos erkennen und sich an sie anpassen, so dass ein kohärenter Dialogfluss aufrechterhalten wird, selbst wenn neue Stimmen oder Befehle eingeführt werden.
- Was macht die mittlere Fusionsstrategie in der LSLM so effektiv? Die mittlere Fusionsstrategie führt Hör- und Sprechkanäle in jedem Transformer-Block zusammen, so dass das Modell während des gesamten Dialogs beide Informationsgruppen nutzen kann. Dieser Ansatz schafft ein Gleichgewicht zwischen Echtzeit-Interaktion und Spracherzeugung und verbessert die Reaktionsfähigkeit und Kohärenz der KI.
- Wie geht die LSLM während ihrer Operationen mit Hintergrundgeräuschen um? In befehlsbasierten Experimenten hat die LSLM ihre Robustheit unter Beweis gestellt, indem sie Hintergrundgeräusche effektiv herausfiltert und sich auf bestimmte Befehle konzentriert. Ihre fortschrittlichen Verarbeitungsfunktionen gewährleisten auch in lauten Umgebungen präzise Antworten.
- Welches sind die möglichen Anwendungen des Listening-While-Speaking Language Model? Das LSLM kann die Interaktion zwischen Mensch und Computer in verschiedenen Bereichen verbessern, z. B. im Kundendienst, bei intelligenten Haushaltsgeräten und virtuellen Assistenten. Seine Fähigkeit, Dialoge und Unterbrechungen in Echtzeit zu verarbeiten, macht es ideal für Szenarien, die eine nahtlose und intuitive Kommunikation erfordern.