
Last Updated on Mai 28, 2024 3:07 pm by Laszlo Szabo / NowadAIs | Published on Mai 28, 2024 by Laszlo Szabo / NowadAIs
AI für gehörlose Menschen: Einführung in SignLLM – Wichtige Hinweise
- SignLLM: Ein bahnbrechendes mehrsprachiges Gebärdensprachproduktionsmodell.
- Prompt2Sign-Datensatz: Ein vielfältiger Datensatz, der das Training von SignLLM unterstützt.
- Mehrsprachige Fähigkeit: Unterstützt acht verschiedene Gebärdensprachen.
- Verstärkungslernen: Verbessert die Trainingseffizienz und die Modellqualität.
- Text-zu-Gloss-Integration: Gewährleistet eine linguistisch korrekte Ausgabe der Gebärdensprache.
- Qualitative Verbesserungen: Erzielt realistische und visuell überzeugende Gebärdensprachegesten.
- Ablationsstudien: Identifiziert die wichtigsten Faktoren für den Erfolg des Modells.
Einführung
Die Gebärdensprache ist für Millionen von Menschen weltweit ein lebenswichtiges Kommunikationsmittel, doch die Entwicklung von Technologien zur Unterstützung und Verbesserung der Gebärdensprachproduktion ist hinter den Fortschritten bei der Verarbeitung gesprochener Sprache zurückgeblieben. Das heißt, bis zur Arbeit der Forscher hinter SignLLM – dem ersten umfassenden mehrsprachigen Gebärdensprachproduktionsmodell.
Jetzt befassen wir uns mit dem innovativen SignLLM-Rahmenwerk und untersuchen seine Grundlagen, die wichtigsten Merkmale und die transformativen Auswirkungen, die es auf den Bereich der Gebärdensprachtechnologie haben wird. Von der Erstellung des Prompt2Sign-Datensatzes bis hin zur Entwicklung neuartiger Techniken zur Erzeugung von Gebärdensprache wird beleuchtet, wie SignLLM die Grenzen dessen, was in der Gebärdensprachproduktion möglich ist, neu definiert.
Der Prompt2Sign-Datensatz: Das Fundament legen
Das Herzstück des SignLLM-Projekts ist der Prompt2Sign-Datensatz – eine bahnbrechende Ressource, die Gebärdensprachdaten aus einer Vielzahl von Quellen zusammenführt, darunter die Amerikanische Gebärdensprache (ASL) und sieben weitere Gebärdensprachen. Durch die sorgfältige Umwandlung einer umfangreichen Sammlung von Videos in ein rationalisiertes, modellfreundliches Format hat der Prompt2Sign-Datensatz die Grundlage für die Entwicklung fortschrittlicher Technologien zur Produktion von Gebärdensprache gelegt.
Eine der größten Herausforderungen bei der Erstellung dieses Datensatzes war die Notwendigkeit, die Daten für das Training mit Übersetzungsmodellen wie seq2seq und text2text zu optimieren. Die Forscher haben sich dieser Herausforderung gestellt und innovative Techniken entwickelt, um sicherzustellen, dass die Daten nicht nur umfassend sind, sondern sich auch perfekt für das Training modernster Modelle zur Erzeugung von Gebärdensprache eignen.
Einführung von SignLLM: LLM für den guten Zweck
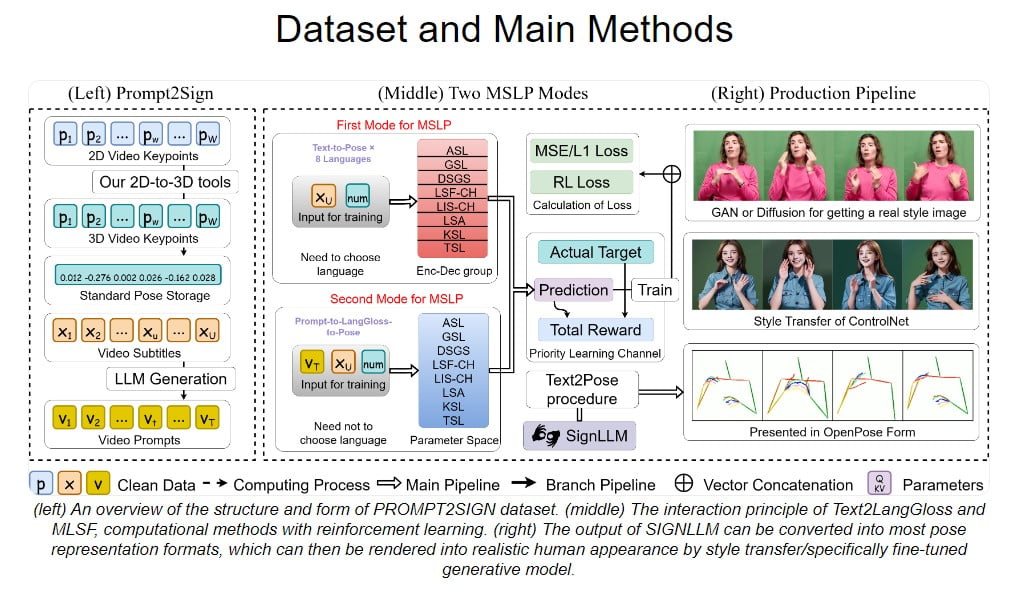
Aufbauend auf der Grundlage des Prompt2Sign-Datensatzes hat das SignLLM-Team ein Modell für die Produktion von Nachrichtenzeichen entwickelt, das einen neuen Standard in diesem Bereich setzt. Dieses mehrsprachige Modell, das erste seiner Art, verfügt über zwei neuartige SLP-Modi (Sign Language Production), die die Erzeugung von Gebärden aus Eingabetexten oder Prompts ermöglichen.
Das Herzstück des Erfolgs von SignLLM ist seine Fähigkeit, eine neue Verlustfunktion und ein auf Verstärkungslernen basierendes Modul zu nutzen. Diese Komponenten arbeiten zusammen, um den Trainingsprozess zu beschleunigen und das Modell in die Lage zu versetzen, selbstständig hochwertige Daten zu sammeln und seine Fähigkeiten zur Erzeugung von Gebärdensprache zu verbessern.
Mehrsprachige Beherrschung: Die Fähigkeiten von SignLLM
Einer der bemerkenswertesten Aspekte von SignLLM ist seine Fähigkeit, die Produktion von Gebärdensprache in mehreren Sprachen nahtlos zu verarbeiten. Durch die Nutzung der Breite des Prompt2Sign-Datensatzes hat das Modell bei SLP-Aufgaben in acht verschiedenen Gebärdensprachen Spitzenleistungen gezeigt, was seine Vielseitigkeit und Anpassungsfähigkeit unter Beweis stellt.
Durch umfangreiche Benchmarking-Untersuchungen haben die Forscher die Leistungsfähigkeit von SignLLM in Bereichen wie der Produktion der Amerikanischen Gebärdensprache (ASLP), der Produktion der Deutschen Gebärdensprache (GSLP) und darüber hinaus unter Beweis gestellt. Diese empirischen Studien haben nicht nur die Effektivität des Modells bestätigt, sondern auch wertvolle Einblicke in die Nuancen und Komplexität der Gebärdenspracherzeugung geliefert.
Verstärkungslernen: Beschleunigung des Trainingsprozesses
Eine Schlüsselinnovation, die SignLLM zugrunde liegt, ist die Einbeziehung von Techniken des verstärkten Lernens. Durch die Nutzung dieses Ansatzes konnten die Forscher die Fähigkeit des Modells, selbstständig qualitativ hochwertige Daten zu sammeln, erheblich verbessern, wodurch der Trainingsprozess beschleunigt und die Gesamtqualität der generierten Gebärden verbessert wurde.
Durch einen iterativen Aktualisierungsprozess, der den Benutzer, den Agenten, die Umgebung und einen Priority Learning Channel (PLC) einbezieht, hat das Verstärkungslernmodul von SignLLM seine Fähigkeit unter Beweis gestellt, die Leistung des Modells zu optimieren, was zu beeindruckenden Ergebnissen bei einer Reihe von Gebärdensprachproduktionsaufgaben führte.
Verbesserung der Gebärdensprachproduktion durch Text-to-Gloss-Integration
Zusätzlich zu seinen Verstärkungslernfähigkeiten hat SignLLM auch von der Integration eines Text-to-Gloss-Frameworks profitiert. Dadurch kann das Modell Gebärdensprachglossen mit den erforderlichen linguistischen Attributen erzeugen und gleichzeitig durch die Verwendung von Variablen innerhalb der Architektur des neuronalen Netzes tiefgreifende Merkmale erfassen.
Durch die nahtlose Verschmelzung dieser textuellen und gestischen Elemente ist SignLLM in der Lage, Gebärdensprachausgaben zu erzeugen, die nicht nur visuell ansprechend, sondern auch sprachlich korrekt und ausdrucksstark sind. Diese Integration von Text-zu-Gesten-Techniken war ein entscheidender Faktor für die Fähigkeit des Modells, bei der Produktion von Gebärdensprache Spitzenleistungen zu erzielen.
Qualitative Verbesserungen: Verbesserung der Realitätsnähe von Gebärdensprachgebärden
Neben seiner beeindruckenden quantitativen Leistung hat SignLLM auch erhebliche Fortschritte bei der Verbesserung der qualitativen Aspekte der Gebärdensprachgenerierung gemacht. Durch die Einbeziehung von Stilübertragungsmodellen und fein abgestimmten generativen Ansätzen konnte das Team die Ausgabe des Modells realistischer und visuell ansprechender gestalten.
Das Ergebnis ist eine Reihe synthetischer Gebärdensprachvideos, die die Nuancen und Feinheiten der menschlichen Gebärdensprache mit bemerkenswerter Genauigkeit wiedergeben. Dieser Fortschritt in der visuellen Qualität der generierten Inhalte verbessert nicht nur das Benutzererlebnis, sondern ebnet auch den Weg für eine nahtlose Integration der Gebärdensprachtechnologie in verschiedene Anwendungen.
Ablationsstudien: Enthüllung der Faktoren für den Erfolg von SignLLM
Um die Faktoren besser zu verstehen, die zu der außergewöhnlichen Leistung von SignLLM beitragen, hat das Forschungsteam eine Reihe von Ablationsstudien durchgeführt. Diese eingehenden Analysen haben die Auswirkungen verschiedener Datenerweiterungstechniken, Verlustfunktionen und Architekturentscheidungen auf die Gesamteffektivität des Modells beleuchtet.
Durch die systematische Evaluierung der Leistung von SignLLM unter verschiedenen Bedingungen konnten die Forscher die wichtigsten Faktoren für den Erfolg des Modells ermitteln. Diese Erkenntnisse fließen nicht nur in künftige Iterationen des SignLLM-Frameworks ein, sondern bieten auch wertvolle Einsichten für die breitere Gemeinschaft der Gebärdensprachtechnologie.
Effizientes Training: Optimierung des Lernprozesses
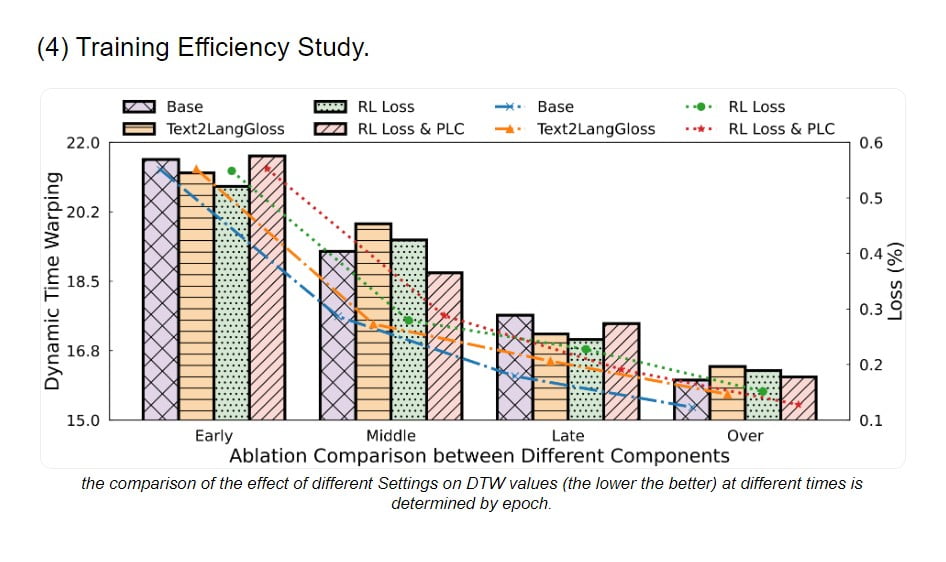
Das SignLLM-Team hat erkannt, wie wichtig die Trainingseffizienz bei der Entwicklung von Modellen für die Produktion von Gebärdensprache in großem Maßstab ist, und hat sich der Optimierung des Lernprozesses gewidmet. Durch sorgfältige Experimente und Analysen haben sie Strategien identifiziert, die das Training von SignLLM erheblich beschleunigen können, ohne die Qualität der generierten Ergebnisse zu beeinträchtigen.
Diese auf Effizienz ausgerichteten Techniken, einschließlich der Verwendung neuartiger Verlustfunktionen und spezieller Trainingsmodule, haben es den Forschern ermöglicht, SignLLM schneller und effektiver zu trainieren, was letztlich zu kürzeren Entwicklungszyklen und einer schnelleren Einführung der Technologie geführt hat.
Überbrückung der Lücke: SignLLMs potenzielle Auswirkungen
Die Einführung von SignLLM ist ein entscheidender Schritt zur Überbrückung der Kluft zwischen der Verarbeitung gesprochener Sprache und der Gebärdensprachtechnologie. Durch die Bereitstellung einer umfassenden, mehrsprachigen Lösung für die Produktion von Gebärdensprache hat dieses bahnbrechende Modell das Potenzial, die Art und Weise zu verändern, wie Menschen mit Hörbehinderungen oder Gehörlosigkeit kommunizieren und sich mit ihrer Umwelt auseinandersetzen.
SignLLM hat nicht nur unmittelbare Auswirkungen auf das Leben von Gebärdensprachbenutzern, sondern ist auch vielversprechend für breitere Anwendungen in Bereichen wie Bildung, Unterhaltung und Barrierefreiheit. Die Forscher, die hinter SignLLM stehen, sind bestrebt, neue Grenzen zu erforschen und den Bereich der Gebärdensprachtechnologie voranzutreiben, während die Technologie weiter entwickelt und ausgebaut wird.
Eine neue Ära der Gebärdensprachtechnologie wird eingeläutet
Die Einführung von SignLLM stellt einen entscheidenden Moment in der Geschichte der Gebärdensprachtechnologie dar. Durch die Nutzung großer Sprachmodelle, mehrsprachiger Datensätze und fortschrittlicher Computer-KI-Techniken hat dieses bahnbrechende Framework das immense Potenzial für die Gebärdensprachproduktion aufgezeigt, ein besser zugänglicher und integrierter Teil unserer digitalen Landschaft zu werden.
Während sich das SignLLM-Projekt weiterentwickelt und ausweitet, bleiben die dahinter stehenden Forscher standhaft in ihrem Engagement, Innovationen voranzutreiben, die Zusammenarbeit zu fördern und Menschen mit Hörbehinderungen oder Gehörlosigkeit in die Lage zu versetzen, effektiver zu kommunizieren und sich mit der Welt auseinanderzusetzen. Die Zukunft der Gebärdensprachtechnologie ist vielversprechend, und SignLLM ist führend auf dem Weg zu einer integrativeren und zugänglicheren Welt.
Definitionen
- SignLLM: Ein umfassendes mehrsprachiges Gebärdensprachproduktionsmodell, das entwickelt wurde, um Gebärden aus Textaufforderungen zu generieren.
- Amerikanische Gebärdensprache (ASL): Eine vollständige, natürliche Sprache, die von der Gehörlosengemeinschaft in den Vereinigten Staaten und Teilen Kanadas verwendet wird.
- Prompt2Sign-Datensatz: Ein Datensatz, der Gebärdensprachdaten aus verschiedenen Quellen enthält und für das Training von Modellen zur Erzeugung von Gebärdensprache optimiert ist.
- Prioritäts-Lernkanal (PLC): Ein auf Verstärkungslernen basierendes Modul, das zur Verbesserung des Trainingsprozesses verwendet wird, indem qualitativ hochwertige Datenproben priorisiert werden.
Häufig gestellte Fragen
- Was ist SignLLM? SignLLM ist ein hochmodernes mehrsprachiges Gebärdensprachproduktionsmodell, das Gebärden aus Textaufforderungen generieren kann. Es unterstützt acht verschiedene Gebärdensprachen, darunter American Sign Language (ASL).
- Wie nutzt SignLLM den Prompt2Sign-Datensatz? Der Prompt2Sign-Datensatz ist eine grundlegende Ressource für SignLLM, die vielfältige und hochwertige Gebärdensprachdaten liefert. Dieser Datensatz ermöglicht es dem Modell, in mehreren Sprachen effektiv zu arbeiten.
- Was ist der Prioritäts-Lernkanal (PLC) in SignLLM? Der Priority Learning Channel (PLC) ist ein Reinforcement-Learning-Modul in SignLLM, das den Trainingsprozess verbessert, indem es selbstständig qualitativ hochwertige Daten abfragt. Dadurch werden die Leistung des Modells und die Trainingseffizienz gesteigert.
- Wie stellt SignLLM die Qualität der generierten Gebärden sicher? SignLLM enthält ein Text-to-Gloss-Framework und Stiltransfermodelle, die dazu beitragen, sprachlich korrekte und visuell überzeugende Gebärden zu erzeugen, und so die Gesamtqualität der Ausgabe verbessern.
- Was sind die möglichen Anwendungen von SignLLM? SignLLM kann in verschiedenen Bereichen wie Bildung, Unterhaltung und Barrierefreiheit eingesetzt werden. Es zielt darauf ab, die Kommunikation für Menschen mit Hörbehinderungen oder Gehörlosigkeit zu verbessern, indem es ein fortschrittliches Werkzeug für die Gebärdensprachproduktion bereitstellt.







