
Last Updated on August 8, 2024 1:28 pm by Laszlo Szabo / NowadAIs | Published on August 8, 2024 by Laszlo Szabo / NowadAIs
YI-VL-34B: Neudefinition der multimodalen KI in Englisch und Chinesisch
- YI-VL-34B ist ein von 01.AI entwickeltes zweisprachiges Sprachmodell, das sowohl in Englisch als auch in Chinesisch brilliert.
- Das Modell ist führend in den MMMU- und CMMMU-Benchmarks und zeigt eine unübertroffene Leistung in multimodaler KI.
- YI-VL-34B ist über Plattformen wie Hugging Face zugänglich, mit Open-Source-Ressourcen für Forscher und Entwickler.
Yi-VL-34B verfügbar
Yi-VL-34B, das von 01.AI entwickelte Open-Source-Vision-Sprachmodell (VLM), hat sich als weltweiter Spitzenreiter im Bereich der multimodalen KI etabliert. Dieses zweisprachige Ungetüm, das sowohl Englisch als auch Chinesisch beherrscht, hat sich bei den Benchmarks MMMU (Multimodal Multidisciplinary Multilingual Understanding) und CMMMU (Chinese Multimodal Multidisciplinary Multilingual Understanding) den begehrten Spitzenplatz unter allen bestehenden Open-Source-Modellen gesichert (Stand Januar 2024).
Multimodale Pionierleistung
Yi-VL-34B ist ein Wegbereiter, der eine neue Ära der multimodalen Intelligenz einläutet. Seine bemerkenswerten Fähigkeiten gehen weit über das reine Textverständnis hinaus und ermöglichen es ihm, visuelle Informationen nahtlos zu interpretieren und mit ihnen zu kommunizieren. Dieses bahnbrechende VLM kann mühelos Bilder verstehen und analysieren, komplizierte Details extrahieren und aufschlussreiche Textbeschreibungen erstellen oder sich an mehrseitigen visuellen Frage-Antwort-Sitzungen beteiligen.
Architektonischer Einfallsreichtum: Das LLaVA-Rahmenwerk
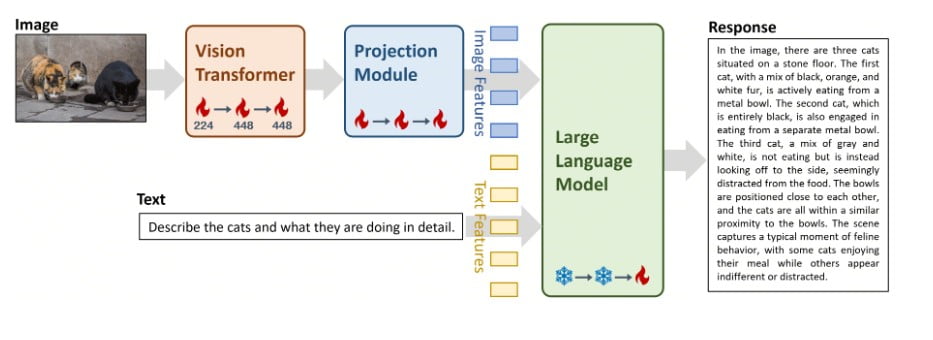

Das Herzstück von Yi-VL-34B ist die ausgeklügelte LLaVA-Architektur (Large Language and Vision Assistant), eine harmonische Verschmelzung dreier wichtiger Komponenten:
- Vision Transformer (ViT): Diese Komponente wird mit dem hochmodernen CLIP ViT-H/14-Modell initialisiert und ist für die Codierung visueller Informationen mit beispielloser Präzision verantwortlich.
- Projektionsmodul: Dieses komplexe Modul wurde entwickelt, um die Lücke zwischen Bild- und Textdarstellungen zu schließen. Es gleicht visuelle Merkmale mit dem textuellen Merkmalsraum ab und gewährleistet so eine nahtlose Integration.
- Großes Sprachmodell (LLM): Diese Komponente ist das Rückgrat der sprachlichen Fähigkeiten von Yi-VL-34B und wird mit dem beeindruckenden Yi-34B-Chat-Modell initialisiert, das für seine außergewöhnlichen zweisprachigen Verständnis- und Generierungsfähigkeiten bekannt ist.
Umfassendes Trainingsprogramm
Um das volle Potenzial von Yi-VL-34B auszuschöpfen, hat 01.AI einen rigorosen dreistufigen Trainingsprozess angewandt, der sorgfältig darauf zugeschnitten ist, visuelle und sprachliche Informationen im semantischen Raum des Modells abzugleichen:
- Stufe 1: Die Parameter des ViT- und Projektionsmoduls wurden mit einer Auflösung von 224×224 Bildern trainiert, wobei ein riesiger Datensatz von 100 Millionen Bild-Text-Paaren aus dem LAION-400M-Korpus verwendet wurde. Ziel dieser ersten Phase war es, das visuelle Verständnis des ViT zu verbessern und eine bessere Abstimmung mit der LLM-Komponente zu erreichen.
- Stufe 2: Die Bildauflösung wurde auf 448×448 skaliert und die Parameter des ViT und des Projektionsmoduls weiter verfeinert. Diese Phase konzentrierte sich auf die Verbesserung der Fähigkeit des Modells, komplizierte visuelle Details zu erkennen, und stützte sich auf einen vielfältigen Datensatz von 25 Millionen Bild-Text-Paaren, darunter LAION-400M, CLLaVA, LLaVAR, Flickr, VQAv2, RefCOCO, Visual7w und andere.
- Stufe 3: Die letzte Stufe umfasste die Feinabstimmung des gesamten Modells, wobei alle Komponenten (ViT, Projektionsmodul und LLM) einem Training unterzogen wurden. Dieser entscheidende Schritt zielte darauf ab, die Fähigkeiten von Yi-VL-34B bei multimodalen Chat-Interaktionen zu verbessern, damit es visuelle und sprachliche Eingaben nahtlos integrieren und interpretieren kann. Der Trainingsdatensatz umfasste etwa 1 Million Bild-Text-Paare aus verschiedenen Quellen, darunter GQA, VizWiz VQA, TextCaps, OCR-VQA, Visual Genome, LAION GPT4V und andere, wobei der maximale Beitrag einer einzelnen Quelle begrenzt war, um die Ausgewogenheit der Daten sicherzustellen.
Unerreichte Leistung: Vorherrschaft im Benchmarking
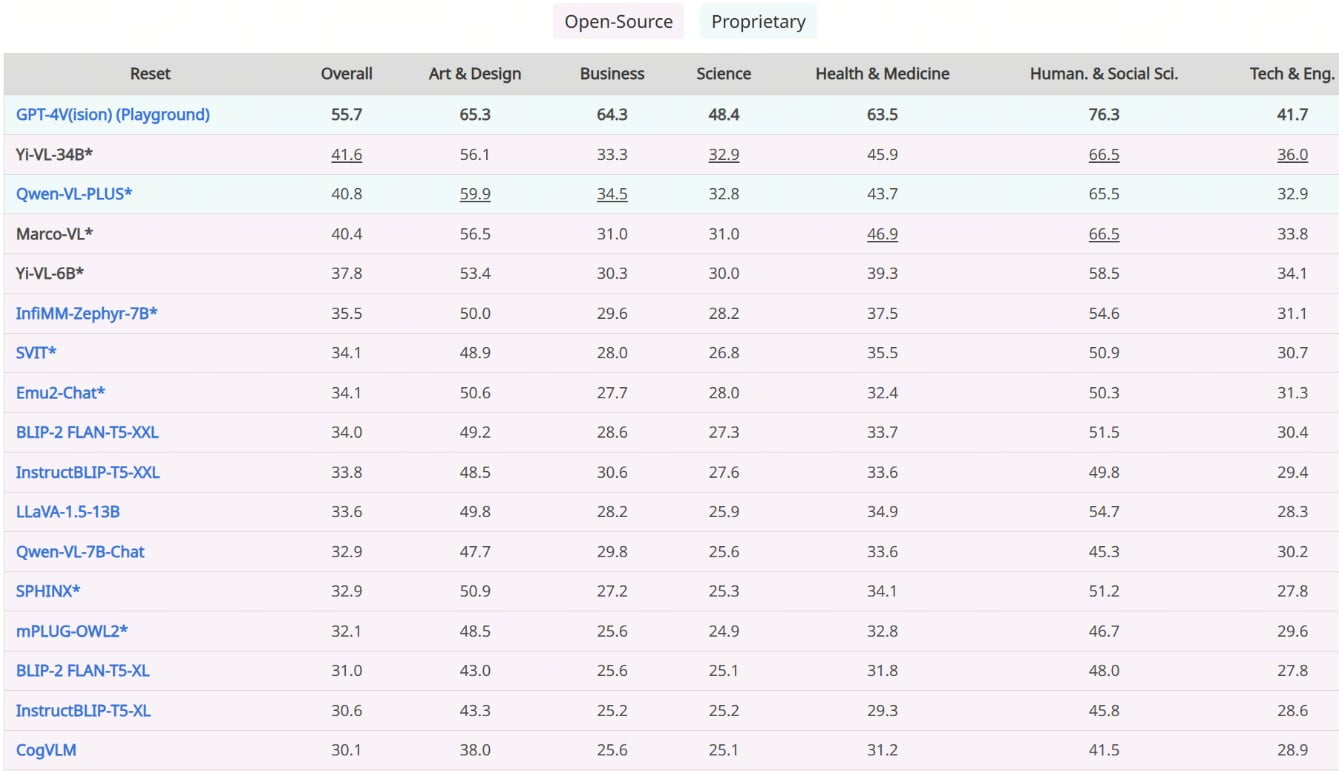
Die Fähigkeiten des Yi-VL-34B zeigen sich in seiner beispiellosen Leistung bei den neuesten Benchmarks, die seine Position als unangefochtener Spitzenreiter unter den Open-Source-VLMs festigt. Bei den MMMU- und CMMMU-Benchmarks, die eine Vielzahl multimodaler Fragen aus verschiedenen Disziplinen umfassen, übertraf Yi-VL-34B alle Konkurrenten und setzte einen neuen Standard für multimodale Open-Source-KI.
Visuelles Verstehen vorführen
Um die bemerkenswerten Fähigkeiten von Yi-VL-34B im Bereich des visuellen Verständnisses zu veranschaulichen, hat 01.AI eine Reihe von fesselnden Beispielen veröffentlicht, die die Fähigkeiten des Modells bei detaillierten Beschreibungen und visuellen Frage-Antwort-Aufgaben zeigen. Diese Beispiele, die sowohl auf Englisch als auch auf Chinesisch verfügbar sind, belegen die Fähigkeit des Modells, komplexe visuelle Szenen mit bemerkenswerter Geläufigkeit und Genauigkeit zu interpretieren und sich darüber zu unterhalten.
Vielfältige Anwendungen ermöglichen
Mit seinen unvergleichlichen multimodalen Fähigkeiten bietet Yi-VL-34B ein immenses Potenzial für eine Vielzahl von Anwendungen, die so unterschiedliche Bereiche wie Computer Vision, Verarbeitung natürlicher Sprache und Multimedia-Analyse umfassen. Von Bildunterschriften und visuellen Fragebeantwortungen bis hin zum Verstehen von Szenen und multimodalen Schlussfolgerungen verspricht dieses bahnbrechende VLM, neue Grenzen für KI-gestützte Lösungen zu eröffnen.
Zugänglichkeit und Benutzerfreundlichkeit
Um eine breite Akzeptanz und Erforschung zu fördern, hat 01.AI Yi-VL-34B über verschiedene Kanäle verfügbar gemacht, darunter die bekannten Plattformen Hugging Face, ModelScope und wisemodel. Egal, ob Sie ein erfahrener Forscher, ein Datenwissenschaftler oder ein KI-Enthusiast sind, der Zugriff auf und das Experimentieren mit Yi-VL-34B war noch nie so einfach.
Hardware-Anforderungen und Überlegungen zum Einsatz
Um das volle Potenzial von Yi-VL-34B nutzen zu können, müssen Benutzer bestimmte Hardwareanforderungen erfüllen. Für eine optimale Leistung empfiehlt die 01.AI den Einsatz des Modells auf High-End-GPUs, wie z. B. vier NVIDIA RTX 4090-GPUs oder eine einzelne A800-GPU mit 80 GB VRAM. Es ist wichtig sicherzustellen, dass Ihre Hardware diese Spezifikationen erfüllt, um die Fähigkeiten des Modells voll auszuschöpfen.
Umfassende Open-Source-Zusammenarbeit
Im Geiste der Open-Source-Innovation dankt 01.AI den Entwicklern und Mitwirkenden verschiedener Open-Source-Projekte, die bei der Entwicklung von Yi-VL-34B eine entscheidende Rolle gespielt haben, und spricht ihnen seinen Dank aus. Dazu gehören die LLaVA-Codebasis, OpenCLIP und andere unschätzbare Ressourcen, die maßgeblich an der Entwicklung dieses VLM beteiligt waren.
Verantwortungsvolle KI und ethische Erwägungen
Obwohl Yi-VL-34B einen bedeutenden Fortschritt in der multimodalen KI darstellt, ist sich 01.AI der potenziellen Risiken und Grenzen bewusst, die mit solch leistungsstarken Modellen verbunden sind. Das Unternehmen betont die Bedeutung verantwortungsvoller KI-Praktiken und ethischer Überlegungen, wobei es die Möglichkeit von Halluzinationen, Auflösungsproblemen und anderen bekannten Einschränkungen anerkennt. 01.01.AI ermutigt die Nutzer, die potenziellen Risiken sorgfältig zu bewerten, bevor sie Yi-VL-34B einsetzen, und das Modell verantwortungsvoll zu nutzen, indem sie sich an ethische Richtlinien und bewährte Verfahren der Datensicherheit halten.
Vorwärts schreiten: Die Zukunft der multimodalen Intelligenz
Die Veröffentlichung von Yi-VL-34B stellt einen wichtigen Meilenstein auf dem Weg zu fortschrittlicheren und leistungsfähigeren multimodalen KI-Systemen dar. Da sich das Feld weiterhin rasant entwickelt, bleibt 01.AI dem Ziel verpflichtet, die Grenzen des Möglichen zu erweitern, die Zusammenarbeit zu fördern und die Innovation auf dem Gebiet der Bildsprachmodelle voranzutreiben.
Mit dem Yi-VL-34B an der Spitze sieht die Zukunft der multimodalen Intelligenz vielversprechender aus als je zuvor und ebnet den Weg für bahnbrechende Anwendungen und Lösungen, die visuelle und sprachliche Informationen nahtlos integrieren. Während die Welt diesen Paradigmenwechsel begrüßt, ist Yi-VL-34B ein Leuchtfeuer der Inspiration, das die Vorstellungskraft von Forschern, Entwicklern und Visionären gleichermaßen beflügelt und uns in eine Zukunft führt, in der KI Grenzen überschreitet und neue Möglichkeiten eröffnet.
Beschreibungen
- Multimodale KI: Ein KI-System, das mehrere Formen von Daten wie Text, Bilder und Audio integriert, um Informationen zu verstehen und zu generieren. Dieser Ansatz ermöglicht eine natürlichere und umfassendere Interaktion mit KI-Modellen.
- Vision Language Model (VLM): Eine Art von KI-Modell, das sowohl visuelle als auch textuelle Daten verstehen und generieren kann. VLMs können Aufgaben wie die Beschriftung von Bildern und die Beantwortung visueller Fragen übernehmen, was sie zu vielseitigen Werkzeugen in der KI-Forschung macht.
- LLaVA-Rahmenwerk: Das Large Language and Vision Assistant Framework, das die Grundlage von YI-VL-34B bildet. Es kombiniert visuelle Daten mit Sprachverständnis, um die Fähigkeit des Modells zur Interpretation und Interaktion mit komplexen Informationen zu verbessern.
- Vision Transformer (ViT): Eine neuronale Netzwerkarchitektur, die visuelle Daten in ähnlicher Weise verarbeitet, wie Sprachmodelle Text verarbeiten. Es wird im YI-VL-34B eingesetzt, um visuelle Informationen mit hoher Präzision zu kodieren.
- Projektionsmodul: Eine Komponente in YI-VL-34B, die visuelle Merkmale mit Text abgleicht und so sicherstellt, dass Bilder und Sprache vom KI-Modell zusammenhängend interpretiert werden.
- Großes Sprachmodell (LLM): Das Herzstück der Sprachverarbeitungsfähigkeiten von YI-VL-34B. Es verarbeitet Textdaten und ermöglicht es dem Modell, kohärente und kontextbezogene Antworten zu generieren.
- Benchmarking-Vorherrschaft: Bezieht sich auf die führende Leistung von YI-VL-34B in Tests, die die Fähigkeiten von KI-Modellen bei der Bewältigung multimodaler und mehrsprachiger Aufgaben messen und damit seine überlegenen Fähigkeiten demonstrieren.
- Multimodales multidisziplinäres mehrsprachiges Verstehen (MMMU): Ein Benchmark, der die Fähigkeiten eines KI-Modells in verschiedenen Disziplinen und Sprachen bewertet und seine Fähigkeit zur Integration und Verarbeitung unterschiedlicher Datentypen prüft.
- Open-Source-Zusammenarbeit: Die Praxis der Entwicklung von Software mit öffentlich zugänglichem Code, der es jedem erlaubt, ihn zu nutzen, zu verändern und zu verbreiten. Die Entwicklung von YI-VL-34B wurde durch Open-Source-Ressourcen wie LLaVA und OpenCLIP unterstützt.
- Ethische KI-Praktiken: Richtlinien, die sicherstellen, dass KI verantwortungsvoll und ethisch korrekt eingesetzt wird, wobei der Schwerpunkt auf Transparenz, Fairness und Schadensminimierung liegt. YI-VL-34B betont, wie wichtig es ist, diese Praktiken bei der Nutzung zu befolgen.
Häufig gestellte Fragen
- Was ist YI-VL-34B und wie funktioniert es? YI-VL-34B ist ein fortschrittliches visuelles Sprachmodell, das Text- und visuelle Daten integriert, um komplexe Aufgaben sowohl in Englisch als auch in Chinesisch auszuführen. Unter Verwendung des LLaVA-Frameworks verarbeitet es multimodale Eingaben, um präzise Antworten und aufschlussreiche Analysen zu generieren.
- Wie übertrifft YI-VL-34B andere Modelle bei den MMMU- und CMMMU-Benchmarks? YI-VL-34B übertrifft andere Modelle aufgrund seiner ausgeklügelten Architektur, die einen Vision Transformer, ein Projektionsmodul und ein Large Language Model kombiniert. Diese Synergie ermöglicht es ihm, bei multimodalen und mehrsprachigen Aufgaben zu glänzen und neue Maßstäbe für die Leistung von Open-Source-KI zu setzen.
- Was sind die praktischen Anwendungen von YI-VL-34B? YI-VL-34B hat eine breite Palette von Anwendungen, einschließlich Bildunterschriften, Beantwortung visueller Fragen und Szenenverständnis. Seine Fähigkeit, sowohl visuelle als auch sprachliche Informationen zu interpretieren, macht es in Bereichen wie Computer Vision, natürliche Sprachverarbeitung und Multimedia-Analyse wertvoll.
- Wie können Entwickler auf YI-VL-34B zugreifen und es nutzen? Entwickler können über Plattformen wie Hugging Face auf YI-VL-34B zugreifen, die Open-Source-Ressourcen für die Integration des Modells in verschiedene Projekte bereitstellen. Diese Zugänglichkeit fördert die Innovation und Zusammenarbeit innerhalb der KI-Gemeinschaft.
- Welche ethischen Überlegungen gibt es bei der Verwendung von YI-VL-34B? Bei der Verwendung von YI-VL-34B ist es von entscheidender Bedeutung, ethische KI-Praktiken zu befolgen, wie z. B. die Gewährleistung des Datenschutzes und die Minimierung potenzieller Verzerrungen in den Ergebnissen des Modells. Die Entwickler sollten diese Faktoren sorgfältig abwägen, um einen verantwortungsvollen Einsatz der Technologie zu gewährleisten.







