
Last Updated on Juli 26, 2024 12:40 pm by Laszlo Szabo / NowadAIs | Published on Juli 24, 2024 by Laszlo Szabo / NowadAIs
12B NeMo-Modell von Mistral AI und NVIDIA veröffentlicht – Wichtige Hinweise
- Mistral AI und NVIDIA haben gemeinsam das 12B NeMo Modell entwickelt.
- NeMo verfügt über ein Kontextfenster von 128.000 Token.
- Das Modell zeichnet sich durch logisches Denken, allgemeines Wissen und Kodiergenauigkeit aus.
- NeMo ist so konzipiert, dass es Mistral 7B aufgrund seiner Standardarchitektur leicht ersetzen kann.
- Open-Source-Verfügbarkeit unter Apache 2.0 Lizenz für vortrainierte Checkpoints.
- NeMo unterstützt FP8-Inferenz ohne Leistungseinbußen.
- Optimiert für globale und mehrsprachige Anwendungen.
- NeMo enthält Tekken, einen Tokeniser mit 30% höherer Komprimierungseffizienz für Quellcode und viele Sprachen.
NeMo AI Model von Schwergewichten der Industrie
Das Unternehmen Mistral AI hat kürzlich sein neues 12B-Modell, NeMo, vorgestellt, das in Zusammenarbeit mit NVIDIA entwickelt wurde. Dieses neueste Modell verfügt über ein Kontextfenster von 128.000 Token und soll in seinem Größenbereich erstklassige Ergebnisse in den Bereichen logisches Denken, Allgemeinwissen und Kodiergenauigkeit erzielen.
Die Partnerschaft zwischen Mistral AI und NVIDIA hat ein Modell hervorgebracht, das nicht nur die Grenzen seiner Leistungsfähigkeit erweitert, sondern auch den Komfort in den Vordergrund stellt. Mistral NeMo wurde entwickelt, um bestehende Systeme, die Mistral 7B verwenden, mühelos zu ersetzen, da es eine Standardarchitektur verwendet.
Leistung des AI-Modells NeMo

Mistral AI hat vor kurzem eine große Entscheidung getroffen, um die Nutzung und Weiterentwicklung ihres Modells zu fördern, indem sie den Zugang zu vortrainierten Checkpoints und instruktionsabgestimmten Checkpoints unter der Apache 2.0 Lizenz zur Verfügung stellt. Es wird erwartet, dass dieser Ansatz der Open-Source-Verfügbarkeit die Aufmerksamkeit sowohl von Forschern als auch von Unternehmen auf sich ziehen wird, was die Integration des Modells in eine Vielzahl von Anwendungen beschleunigen könnte.
Ein Schlüsselaspekt von Mistral NeMo ist seine Fähigkeit, die Quantisierung während des Trainings zu berücksichtigen, was eine FP8-Inferenz ohne Leistungseinbußen ermöglicht. Diese Funktion könnte für Unternehmen, die große Sprachmodelle effizient implementieren wollen, von großem Nutzen sein.
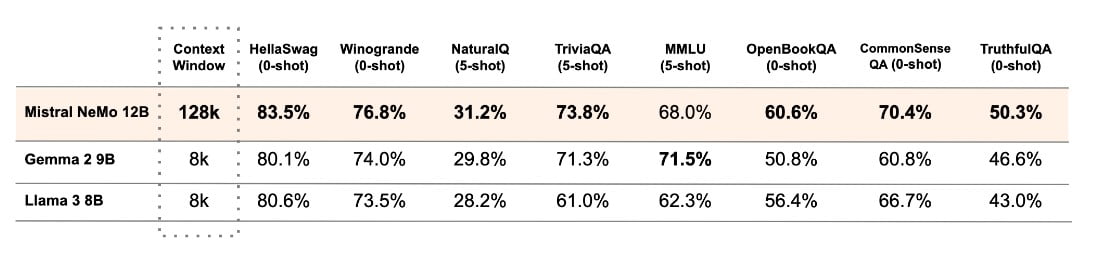
Mistral AI hat eine Leistungsanalyse des Mistral NeMo-Basismodells und zweier anderer vor-trainierter Open-Source-Modelle, nämlich Gemma 2 9B und Llama 3 8B, durchgeführt und einen Vergleich zwischen ihren Leistungen erstellt.
Die Leistung des Modells ist für den Einsatz in globalen und mehrsprachigen Anwendungen optimiert. Sein Training konzentriert sich auf Funktionsaufrufe und es verfügt über ein breites Kontextfenster, wodurch es besonders gut in verschiedenen Sprachen wie Englisch, Französisch, Deutsch, Spanisch, Italienisch, Portugiesisch, Chinesisch, Japanisch, Koreanisch, Arabisch und Hindi funktioniert.
Das Tekken
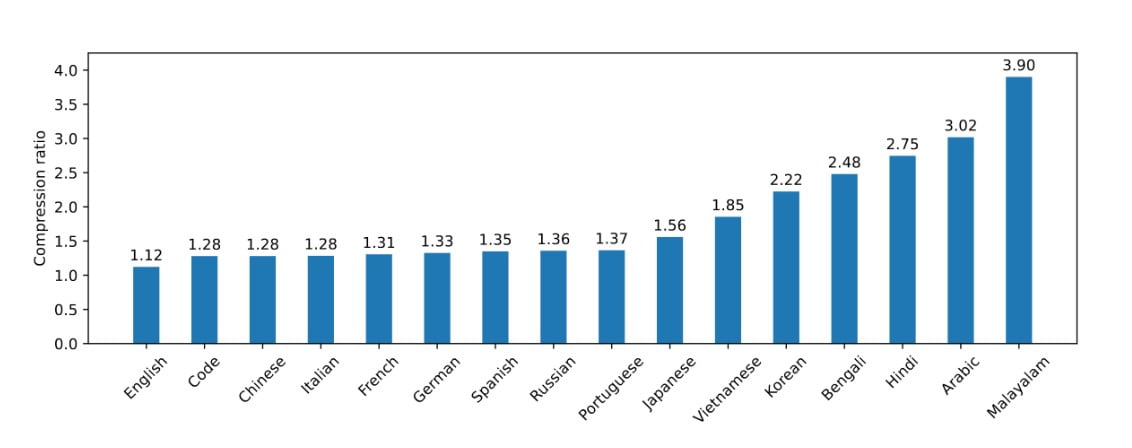
Mistral NeMo hat kürzlich Tekken auf den Markt gebracht, einen neuartigen Tokenisierer, der auf Tiktoken aufbaut. Dieser neue Tokenisierer wurde auf einer Reihe von mehr als 100 Sprachen trainiert. Tekken bietet verbesserte Komprimierungsfähigkeiten sowohl für natürlichsprachlichen Text als auch für Quellcode und übertrifft damit die Leistung des SentencePiece-Tokenisers, der in früheren Mistral-Modellen verwendet wurde. Nach Angaben des Unternehmens ist Tekken in der Lage, eine um 30 % höhere Komprimierungseffizienz für Quellcode und mehrere weit verbreitete Sprachen zu erreichen, wobei die Verbesserungen für Koreanisch und Arabisch noch deutlicher ausfallen.
Laut Mistral AI hat Tekken eine höhere Textkompressionsleistung im Vergleich zum Llama 3 Tokeniser in etwa 85% der Sprachen. Dies könnte Mistral NeMo einen Wettbewerbsvorteil bei mehrsprachigen Anwendungen verschaffen.
Die Gewichte des Modells können jetzt auf HuggingFace sowohl für die Basis- als auch für die Instruct-Version eingesehen werden. Entwickler können mit der Erforschung von Mistral NeMo beginnen, indem sie das Mistral-Inferenz-Tool verwenden und es mit mistral-finetune modifizieren. Für Benutzer der Mistral-Plattform kann das Modell unter dem Namen open-mistral-nemo gefunden werden.
Um die Partnerschaft mit NVIDIA zu würdigen, wird Mistral NeMo auch als NVIDIA NIM Inferenz Microservice auf ai.nvidia.com angeboten. Diese Einbeziehung kann den Implementierungsprozess für Unternehmen erleichtern, die bereits das KI-Ökosystem von NVIDIA nutzen.
Die Einführung von Mistral NeMo ist ein bemerkenswerter Fortschritt, um fortschrittliche KI-Modelle für alle zugänglich zu machen. Dieses von Mistral AI und NVIDIA entwickelte Modell bietet hohe Leistung, mehrsprachige Fähigkeiten und ist frei verfügbar, was es zu einer vielseitigen Lösung für eine Vielzahl von KI-Anwendungen in verschiedenen Branchen und Forschungsbereichen macht.
Definitionen
- LLM Halluzinieren: Wenn große Sprachmodelle plausible, aber falsche oder unsinnige Ausgaben erzeugen.
- HaluBench: Ein Benchmark-Datensatz, der zur Bewertung der Genauigkeit von KI-Modellen bei der Erkennung von Halluzinationen verwendet wird und verschiedene reale Themen abdeckt.
- PubMedQA-Datensatz: Ein Datensatz zur Bewertung von KI-Modellen im Bereich der Beantwortung medizinischer Fragen, um die Genauigkeit in medizinischen Kontexten zu gewährleisten.
- FSDP-Maschinenlerntechnik: Fully Sharded Data Parallelism, eine Technik zur Verbesserung der Effizienz und Skalierbarkeit des Trainings großer Sprachmodelle durch die Verteilung von Daten und Berechnungen auf mehrere GPUs.
Häufig gestellte Fragen
1. Was ist das NeMo-Modell von Mistral AI? Das NeMo-Modell von Mistral AI ist ein KI-Modell mit 12 Milliarden Parametern, das in Zusammenarbeit mit NVIDIA entwickelt wurde und sich durch logisches Denken, allgemeines Wissen und präzise Kodierung auszeichnet.
2. Wie unterscheidet sich das NeMo-Modell von früheren Modellen wie Mistral 7B? NeMo bietet ein deutlich größeres Kontextfenster von 128.000 Token und eine verbesserte Leistung beim schlussfolgernden Denken und bei der Kodierung, was es zu einem überlegenen Ersatz für Mistral 7B macht.
3. Was sind die Hauptmerkmale von NeMo? NeMo bietet ein großes Kontextfenster, Unterstützung für FP8-Inferenz, mehrsprachige Funktionen und verwendet den neuen Tekken-Tokeniser für eine verbesserte Komprimierungseffizienz.
4. Wie geht NeMo mit mehrsprachigen Anwendungen um? NeMo ist für globale Anwendungen optimiert und unterstützt mehrere Sprachen wie Englisch, Französisch, Deutsch, Spanisch, Italienisch, Portugiesisch, Chinesisch, Japanisch, Koreanisch, Arabisch und Hindi.
5. Was ist der Tekken-Tokenisierer, und wie verbessert er die Leistung? Tekken ist ein neuer Tokenisierer, der auf Tiktoken aufbaut und im Vergleich zu früheren Tokenisierern eine 30 % höhere Komprimierungsleistung für natürlichsprachliche Texte und Quellcode bietet.







