Last Updated on August 8, 2024 1:18 pm by Laszlo Szabo / NowadAIs | Published on August 8, 2024 by Laszlo Szabo / NowadAIs
YI-VL-34B: Redefining Multimodal AI in English and Chinese – Key Notes
- YI-VL-34B is a bilingual vision language model excelling in both English and Chinese, developed by 01.AI.
- The model leads in the MMMU and CMMMU benchmarks, showcasing unmatched performance in multimodal AI.
- YI-VL-34B is accessible through platforms like Hugging Face, with open-source resources for researchers and developers.
Yi-VL-34B Available
Yi-VL-34B, the open-source vision language model (VLM) developed by 01.AI, has etched its name as the global frontrunner in the realm of multimodal AI. This bilingual behemoth, adept in both English and Chinese, has secured the coveted top spot among all existing open-source models on the MMMU (Multimodal Multidisciplinary Multilingual Understanding) and CMMMU (Chinese Multimodal Multidisciplinary Multilingual Understanding) benchmarks, as of January 2024.
Pioneering Multimodal Prowess
Yi-VL-34B stands as a trailblazer, ushering in a new era of multimodal intelligence. Its remarkable capabilities extend far beyond mere text comprehension, enabling it to seamlessly interpret and converse about visual information. This groundbreaking VLM can effortlessly comprehend and analyze images, extracting intricate details and generating insightful textual descriptions or engaging in multi-round visual question-answering sessions.
Architectural Ingenuity: The LLaVA Framework
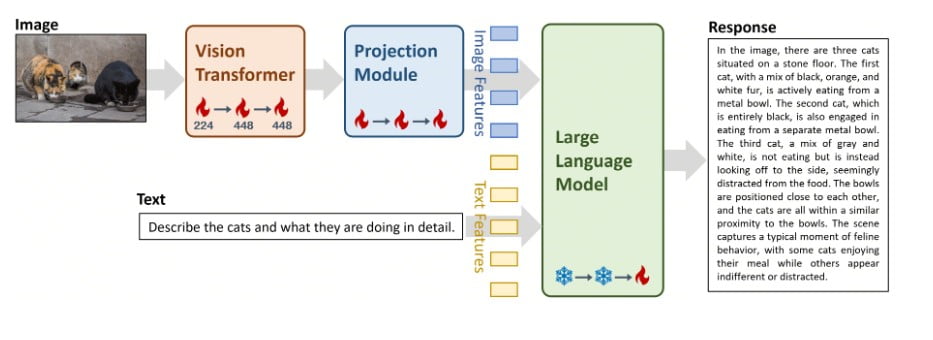
At the core of Yi-VL-34B lies the ingenious LLaVA (Large Language and Vision Assistant) architecture, a harmonious fusion of three critical components:
- Vision Transformer (ViT): Initialized with the state-of-the-art CLIP ViT-H/14 model, this component is responsible for encoding visual information with unparalleled precision.
- Projection Module: Designed to bridge the gap between image and text representations, this intricate module aligns visual features with the textual feature space, ensuring seamless integration.
- Large Language Model (LLM): The backbone of Yi-VL-34B’s linguistic prowess, this component is initialized with the formidable Yi-34B-Chat model, renowned for its exceptional bilingual understanding and generation capabilities.
Comprehensive Training Regimen
To unlock Yi-VL-34B’s full potential, 01.AI employed a rigorous three-stage training process, meticulously tailored to align visual and linguistic information within the model’s semantic space:
- Stage 1: The ViT and projection module parameters were trained using a 224×224 image resolution, leveraging a massive dataset of 100 million image-text pairs from the LAION-400M corpus. This initial stage aimed to enhance the ViT’s visual understanding and achieve better alignment with the LLM component.
- Stage 2: The image resolution was scaled up to 448×448, further refining the ViT and projection module parameters. This stage focused on boosting the model’s ability to discern intricate visual details, drawing from a diverse dataset of 25 million image-text pairs, including LAION-400M, CLLaVA, LLaVAR, Flickr, VQAv2, RefCOCO, Visual7w, and more.
- Stage 3: The final stage involved fine-tuning the entire model, with all components (ViT, projection module, and LLM) undergoing training. This crucial step aimed to enhance Yi-VL-34B’s proficiency in multimodal chat interactions, enabling it to seamlessly integrate and interpret visual and linguistic inputs. The training dataset comprised approximately 1 million image-text pairs from various sources, including GQA, VizWiz VQA, TextCaps, OCR-VQA, Visual Genome, LAION GPT4V, and others, with a cap on the maximum contribution from any single source to ensure data balance.
Unparalleled Performance: Benchmarking Supremacy
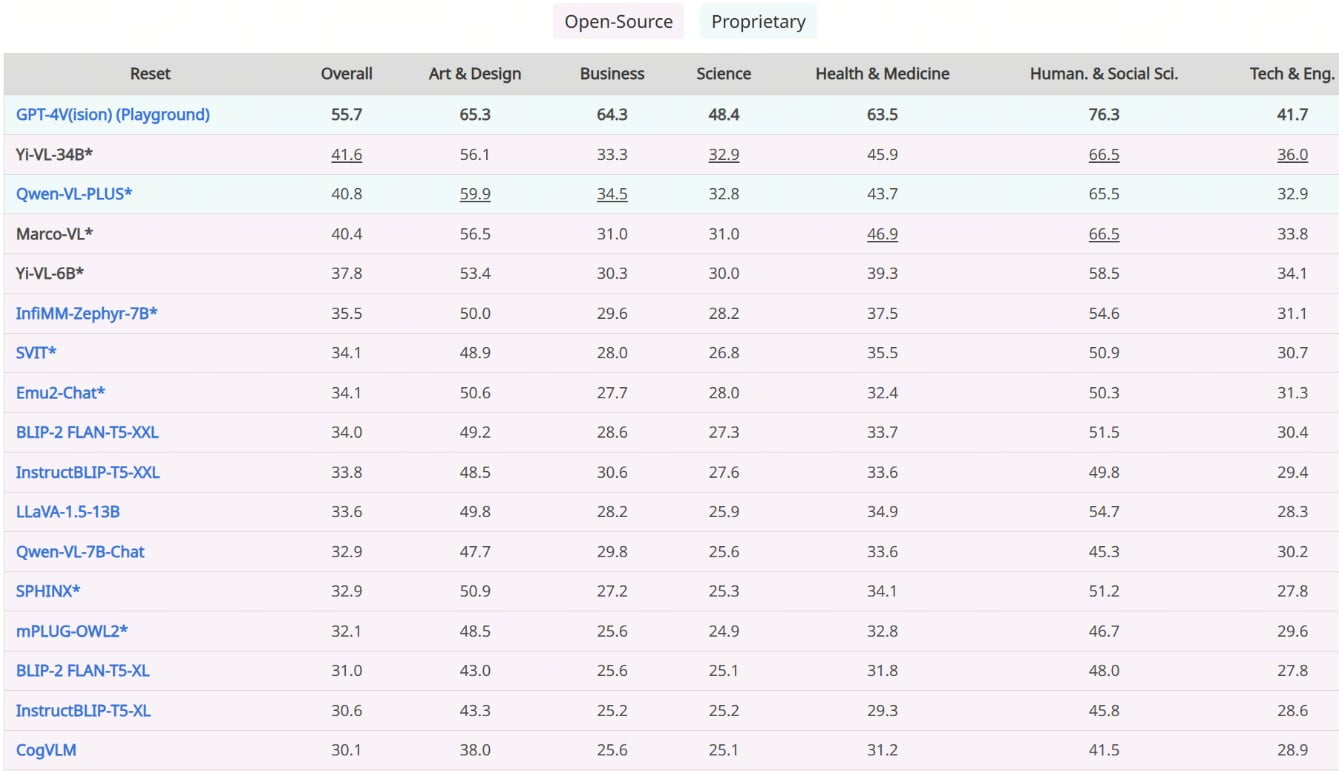
Yi-VL-34B’s prowess is evident in its unparalleled performance on the latest benchmarks, solidifying its position as the undisputed leader among open-source VLMs. On the MMMU and CMMMU benchmarks, which encompass a vast array of multimodal questions spanning multiple disciplines, Yi-VL-34B outshone all contenders, setting a new standard for open-source multimodal AI.
Showcasing Visual Comprehension
To illustrate Yi-VL-34B’s remarkable visual comprehension capabilities, 01.AI has shared a series of captivating examples, showcasing the model’s prowess in detailed description and visual question-answering tasks. These samples, available in both English and Chinese, serve as a testament to the model’s ability to interpret and converse about intricate visual scenes with remarkable fluency and accuracy.
Empowering Diverse Applications
With its unparalleled multimodal capabilities, Yi-VL-34B holds immense potential for a wide range of applications, spanning fields as diverse as computer vision, natural language processing, and multimedia analysis. From image captioning and visual question-answering to scene understanding and multimodal reasoning, this groundbreaking VLM promises to unlock new frontiers in AI-powered solutions.
Accessibility and Ease of Use
To foster widespread adoption and exploration, 01.AI has made Yi-VL-34B readily available through various channels, including the renowned Hugging Face, ModelScope, and wisemodel platforms. Whether you’re a seasoned researcher, a data scientist, or an AI enthusiast, accessing and experimenting with Yi-VL-34B has never been more convenient.
Hardware Requirements and Deployment Considerations
To harness the full potential of Yi-VL-34B, users must meet specific hardware requirements. For optimal performance, 01.AI recommends deploying the model on high-end GPUs, such as four NVIDIA RTX 4090 GPUs or a single A800 GPU with 80GB of VRAM. It’s crucial to ensure that your hardware meets these specifications to experience the model’s capabilities to the fullest.
Embracing Open-Source Collaboration
In keeping with the spirit of open-source innovation, 01.AI acknowledges and expresses gratitude to the developers and contributors of various open-source projects that have played a pivotal role in the development of Yi-VL-34B. This includes the LLaVA codebase, OpenCLIP, and other invaluable resources, which have been instrumental in shaping this VLM.
Responsible AI and Ethical Considerations
While Yi-VL-34B represents a significant stride in multimodal AI, 01.AI recognizes the potential risks and limitations associated with such powerful models. The company emphasizes the importance of responsible AI practices and ethical considerations, acknowledging the possibility of hallucinations, resolution issues, and other known limitations. 01.AI encourages users to carefully evaluate potential risks before adopting Yi-VL-34B and to use the model responsibly, adhering to ethical guidelines and data security best practices.
Forging Ahead: The Future of Multimodal Intelligence
The release of Yi-VL-34B marks a significant milestone in the journey towards more advanced and capable multimodal AI systems. As the field continues to evolve rapidly, 01.AI remains committed to pushing the boundaries of what is possible, fostering collaboration, and driving innovation in the realm of vision language models.
With Yi-VL-34B leading the charge, the future of multimodal intelligence looks brighter than ever, paving the way for groundbreaking applications and solutions that seamlessly integrate visual and linguistic information. As the world embraces this paradigm shift, Yi-VL-34B stands as a beacon of inspiration, igniting the imagination of researchers, developers, and visionaries alike, propelling us towards a future where AI transcends boundaries and unlocks new realms of possibility.
Descriptions
- Multimodal AI: An AI system that integrates multiple forms of data such as text, images, and audio to understand and generate information. This approach allows for more natural and comprehensive interactions with AI models.
- Vision Language Model (VLM): A type of AI model designed to understand and generate both visual and textual data. VLMs can perform tasks like image captioning and visual question answering, making them versatile tools in AI research.
- LLaVA Framework: The Large Language and Vision Assistant framework that forms the foundation of YI-VL-34B. It combines visual data with language understanding to enhance the model’s ability to interpret and interact with complex information.
- Vision Transformer (ViT): A neural network architecture that processes visual data in a way similar to how language models process text. It is used in YI-VL-34B to encode visual information with high precision.
- Projection Module: A component in YI-VL-34B that aligns visual features with text, ensuring that images and language are interpreted cohesively by the AI model.
- Large Language Model (LLM): The core of YI-VL-34B’s language processing capabilities. It handles text data, enabling the model to generate coherent and contextually relevant responses.
- Benchmarking Supremacy: Refers to YI-VL-34B’s leading performance in tests that measure AI models’ abilities to handle multimodal and multilingual tasks, demonstrating its superior capabilities.
- Multimodal Multidisciplinary Multilingual Understanding (MMMU): A benchmark that evaluates an AI model’s proficiency across various disciplines and languages, testing its ability to integrate and process different types of data.
- Open-Source Collaboration: The practice of developing software with publicly accessible code that allows anyone to use, modify, and distribute it. YI-VL-34B’s development was supported by open-source resources like LLaVA and OpenCLIP.
- Ethical AI Practices: Guidelines that ensure AI is used responsibly and ethically, focusing on transparency, fairness, and minimizing harm. YI-VL-34B emphasizes the importance of adhering to these practices during its use.
Frequently Asked Questions
- What is YI-VL-34B and how does it work? YI-VL-34B is an advanced vision language model that integrates text and visual data to perform complex tasks in both English and Chinese. Utilizing the LLaVA framework, it processes multimodal inputs to generate accurate responses and insightful analyses.
- How does YI-VL-34B outperform other models on the MMMU and CMMMU benchmarks? YI-VL-34B surpasses other models due to its sophisticated architecture, which combines a Vision Transformer, a projection module, and a Large Language Model. This synergy allows it to excel in multimodal and multilingual tasks, setting new standards for open-source AI performance.
- What are the practical applications of YI-VL-34B? YI-VL-34B has a wide range of applications, including image captioning, visual question answering, and scene understanding. Its ability to interpret both visual and linguistic information makes it valuable in fields like computer vision, natural language processing, and multimedia analysis.
- How can developers access and use YI-VL-34B? Developers can access YI-VL-34B via platforms like Hugging Face, which provide open-source resources for integrating the model into various projects. This accessibility fosters innovation and collaboration within the AI community.
- What are the ethical considerations when using YI-VL-34B? When using YI-VL-34B, it is crucial to follow ethical AI practices, such as ensuring data privacy and minimizing potential biases in the model’s outputs. Developers should carefully evaluate these factors to ensure responsible deployment of the technology.