
Last Updated on July 24, 2024 12:30 pm by Laszlo Szabo / NowadAIs | Published on July 24, 2024 by Laszlo Szabo / NowadAIs
12B NeMo Model Released by Mistral AI and NVIDIA – Key Notes
- Mistral AI and NVIDIA have collaborated to create the 12B NeMo model.
- NeMo features a context window of 128,000 tokens.
- The model excels in reasoning, general knowledge, and coding precision.
- NeMo is designed to replace Mistral 7B easily due to its standard architecture.
- Open-source availability under Apache 2.0 license for pre-trained checkpoints.
- NeMo supports FP8 inference without performance loss.
- Optimized for global and multilingual applications.
- NeMo includes Tekken, a tokeniser with 30% higher compression efficiency for source code and many languages.
NeMo AI Model by Industry Heavyweights
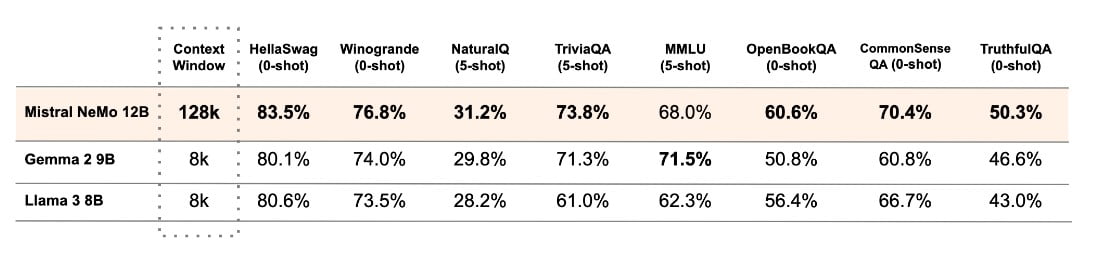
The company Mistral AI has recently revealed their new 12B model, NeMo, which was developed in collaboration with NVIDIA. This latest model has a context window of 128,000 tokens and is said to achieve top-notch results in reasoning, general knowledge, and coding precision within its size range.
The partnership between Mistral AI and NVIDIA has produced a model that not only expands the limits of its performance, but also prioritizes convenience. Mistral NeMo is created to effortlessly replace existing systems that use Mistral 7B, due to its use of standard architecture.
Performance of NeMo AI Model
Mistral AI has recently made a huge decision to promote the use and advancement of their model by providing access to pre-trained checkpoints and instruction-tuned checkpoints under the Apache 2.0 license. This approach of open-source availability is expected to attract the attention of both researchers and businesses, potentially expediting the integration of the model into a variety of applications.

A key aspect of Mistral NeMo is its ability to be aware of quantisation during training, allowing for FP8 inference without sacrificing performance. This feature could be highly beneficial for organizations aiming to efficiently implement large language models.
Mistral AI has conducted a performance analysis of the Mistral NeMo base model and two other open-source pre-trained models, namely Gemma 2 9B and Llama 3 8B, and has provided a comparison between their performances.
The performance of the model is optimized for use in global and multilingual applications. Its training is focused on function calling and it possesses a wide context window, making it especially proficient in various languages such as English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
The Tekken
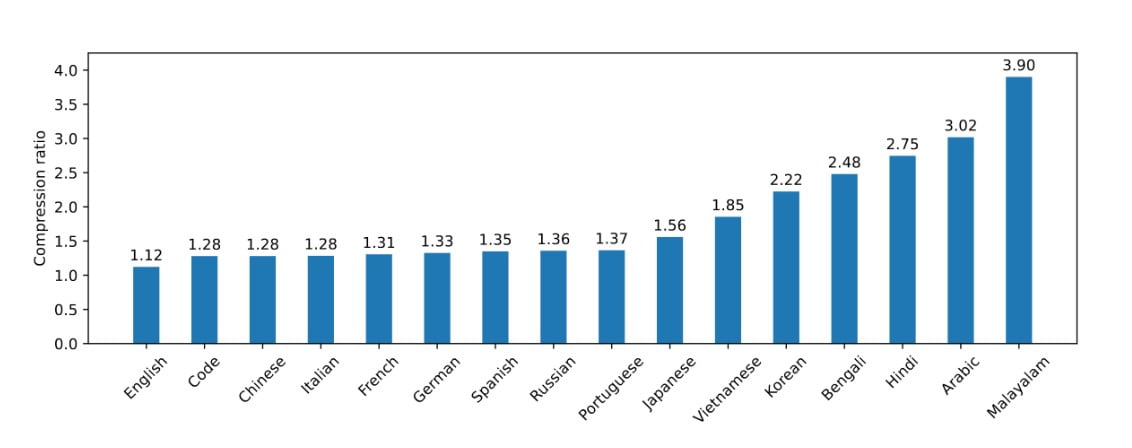
Mistral NeMo has recently launched Tekken, a novel tokeniser that is built upon Tiktoken. This new tokeniser has been trained on a diverse set of more than 100 languages. Tekken boasts of enhanced compression capabilities for both natural language text and source code, surpassing the performance of the SentencePiece tokeniser utilized in previous Mistral models. According to the company, Tekken is able to achieve a compression efficiency that is 30% higher for source code and several widely spoken languages, with even more substantial improvements for Korean and Arabic.
According to Mistral AI, Tekken has a higher text compression performance compared to the Llama 3 tokeniser in approximately 85% of languages. This could potentially provide Mistral NeMo with a competitive advantage in multilingual applications.
The weights of the model can now be accessed on HuggingFace for both the base and instruct versions. Developers can begin exploring Mistral NeMo by utilizing the mistral-inference tool and modifying it with mistral-finetune. For users of Mistral’s platform, the model can be found under the name open-mistral-nemo.
As a way to acknowledge the partnership with NVIDIA, Mistral NeMo is also offered as an NVIDIA NIM inference microservice on ai.nvidia.com. This inclusion may facilitate the implementation process for companies that are already utilizing NVIDIA’s AI ecosystem.
The launch of Mistral NeMo marks a notable progress in making advanced AI models accessible to all. This model, developed by Mistral AI and NVIDIA, offers high performance, multilingual abilities, and is openly available, making it a versatile solution for a variety of AI uses in different industries and research domains.
Definitions
- LLM Hallucinating: When large language models generate plausible but incorrect or nonsensical outputs.
- HaluBench: A benchmark dataset used to evaluate the accuracy of AI models in detecting hallucinations, covering diverse real-world topics.
- PubMedQA Dataset: A dataset designed to evaluate AI models in the domain of medical question-answering, ensuring accuracy in medical contexts.
- FSDP Machine Learning Technique: Fully Sharded Data Parallelism, a technique used to improve the efficiency and scalability of training large language models by distributing data and computations across multiple GPUs.
Frequently Asked Questions
1. What is the NeMo Model by Mistral AI? The NeMo Model by Mistral AI is a 12-billion parameter AI model developed in collaboration with NVIDIA, designed to excel in reasoning, general knowledge, and coding precision.
2. How does the NeMo Model differ from previous models like Mistral 7B? NeMo offers a significantly larger context window of 128,000 tokens and improved performance in reasoning and coding, making it a superior replacement for the Mistral 7B.
3. What are the key features of NeMo? NeMo includes a large context window, support for FP8 inference, multilingual capabilities, and uses the new Tekken tokeniser for enhanced compression efficiency.
4. How does NeMo handle multilingual applications? NeMo is optimized for global applications, supporting multiple languages such as English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
5. What is the Tekken tokeniser, and how does it improve performance? Tekken is a new tokeniser built upon Tiktoken, offering 30% higher compression efficiency for natural language text and source code compared to previous tokenisers.







